
늦깎이 공대생의 인공지능 연구실
[해석할 수 있는 기계학습(7-1)]학습된 특성(Learned Features) 본문
합성곱 신경망(Convolutional Neural Netowrk)은 원본 이미지의 픽셀에서 추상적인 특성과 개념을 학습합니다. 특성시각화(Feature Visualization)은 활성 최대화에 의해 학습된 특성들을 시각화합니다. 신경망 해부(Network Disserction)는 신경망 단위(채널)를 사람의 개념을 기준으로 분류합니다.
심층신경망(Deep Neural Network)은 숨겨진 레이어인 은닉층(Hidden layer) 내의 고차원적인 특성을 학습합니다. 이는 가장 큰 장점이자 특성 공학(Feature Engineering)의 필요성을 줄여줍니다. 여러분이 SVM(Support Vector Machine)으로 이미지 분류기를 만들려 한다고 가정해봅니다. 원본이미지의 픽셀 메트릭스값은 SVM을 학습시키는데 가장 적합한 입력값이 아니므로 색상, 주파수영역, 엣지검출기(Edge Detector) 등에 따라 새 특성을 생성합니다. 픽셀값은 원본 형태로 CNN에 입력됩니다. 신경망은 매번 이미지를 변환합니다. 먼저, 이미지는 많은 합성곱 레이어를 거칩니다. 이러한 합성곱 계층에서 네트워크는 계층에서 새롭고 점점 더 복잡해지는 특징을 학습합니다. 그런 다음 변환된 이미지 정보가 완전히 연결된 계층을 통과하여 분류 또는 예측으로 바뀝니다.

- 첫 번째 합성곱 계층은 엣지 및 간단한 텍스처와 같은 특성을 학습합니다.
- 이후 합성곱 계층은 보다 복잡한 텍스처 및 패턴과 같은 특성을 학습합니다.
- 마지막 합성곱 계층은 객체나 객체의 일부와 같은 특성을 학습합니다.
- 완전히 연결된 계층은 상위 수준의 특성에서 예측될 개별 클래스에 대한 활성화를 연결하는 방법을 학습합니다.
좋습니다. 하지만 이러한 환각적인 이미지를 어떻게 얻을 수 있을까요?
특성 시각화
학습된 특성을 명시적으로 만드는 방법을 특성 시각화(Feature Visualization)라고 합니다. 신경망의 특성 시각화는 해당 네트워크의 활성화를 최대화하는 입력을 찾아 수행됩니다.
"단위"는 개별 뉴런, 채널(특성 맵이라고도 함), 전체 계층 또는 분류의 최종 클래스 확률(또는 권장되는 해당 pre-softmax 뉴런)을 나타냅니다. 개별 뉴런은 신경망의 원자 단위입니다. 그래서 우리는 각각의 뉴런에 대한 특성 시각화를 만들어냄으로써 가장 많은 정보를 얻을 수 있습니다. 하지만 문제가 있습니다. 신경망은 종종 수백만 개의 뉴런을 포함합니다. 각 뉴런의 특성을 보는 것은 시간이 너무 오래 걸릴 것입니다. 하나의 단위로써의 채널(활성화 맵이라고도 함)은 특성을 시각화하는 데 적합합니다. 한 단계 더 나아가서 전체 합성곱 계층을 시각화할 수 있습니다. 단위는 구글의 딥드림(DeepDream)에 사용되며, 기존 이미지에 계층의 시각화 기능을 반복적으로 추가해 꿈 같은 버전의 입력이 가능합니다.
최적화를 통한 특성 시각화
수학적 용어로 특성 시각화는 최적화 문제입니다. 우리는 신경망의 가중치가 고정되어 있습니다고 가정하며, 이는 신경망이 학습되었다는 것을 의미합니다. 우리는 한 단위의 (평균) 활성화를 극대화하는 새로운 이미지를 찾고 있습니다. 여기 단일 뉴런이 있습니다.
$$img^*=\arg\max_{img}h_{n,x,y,z}(img)$$
함수 \(h\)는 뉴런의 활성화로, 신경망의 입력을 가져오고, x와 y는 뉴런의 공간 위치를 설명하고, n은 레이어를 지정하고 z는 채널 인덱스입니다. 계층 n에서 전체 채널 z의 평균 활성화를 위해 다음을 최대화합니다.
$$img^*=\arg\max_{img}\sum_{x,y}h_{n,x,y,z}(img)$$
이 공식에서, 채널 z의 모든 뉴런은 동일한 가중치를 가집니다. 또는 임의의 방향으로 최대화할 수 있습니다. 즉, 뉴런이 음의 방향을 포함하여 서로 다른 파라미터로 곱해지는 것입니다. 이런 식으로, 우리는 뉴런들이 어떻게 채널 안에서 상호작용하는지 연구합니다. 활성화를 최대화하는 대신 활성화(음의 방향 최대화에 해당)를 최소화할 수도 있습니다. 흥미롭게도 음의 방향을 최대화하면 동일한 단위에 대해 매우 다른 특성을 얻을 수 있습니다.

이 최적화 문제를 다양한 방법으로 해결할 수 있습니다. 먼저, 왜 우리는 새로운 이미지를 생성해야만 할까요? 우리는 단순히 우리의 학습 이미지를 검색하고 활성화를 극대화하는 이미지를 선택할 수 있습니다. 이것은 유효한 접근법입니다. 하지만 학습 데이터를 사용하는 것은 이미지의 요소들이 상호 연관될 수 있다는 문제를 가지고 있습니다. 그리고 우리는 신경망이 실제로 무엇을 찾고 있는지 알 수 없습니다. 특정 채널의 높은 활성화를 산출하는 이미지가 개와 테니스공을 보여준다면 신경망이 개를 보는지, 테니스공을 보는지, 아니면 둘 다 보는지 알 수 없습니다.
또 다른 방법은 랜덤 노이즈에서 시작하여 새 이미지를 생성하는 것입니다. 의미 있는 시각화를 얻기 위해 이미지에는 일반적으로 작은 변경만 허용됩니다. 특성 시각화의 노이즈를 줄이기 위해 최적화 단계 전에 이미지에 jittering, 회전 또는 배율을 적용할 수 있습니다. 다른 정규화 옵션에는 빈도 벌칙화(예: 인접 픽셀의 분산 감소) 또는 학습된 이전 버전(예: 생산적 적대적 네트워크(GAN) 또는 노이즈 제거 자동 인코더(denoising autoencoders) )가 포함됩니다.

특성 시각화에 대해 더 깊이 알고 싶다면, distill.pub 온라인 저널, 특히 Olah et al.의 특성 시각화 게시물을 살펴보세요. 이 게시물은 제가 많은 이미지를 사용했고 해석력의 구성 요소에 대해서도 다루었습니다.
적대적 예제로의 연결
특성 시각화와 적대적 예제 사이에는 연관성이 있습니다. 두 기법 모두 신경망 단위의 활성화를 극대화합니다. 적대적 예제의 경우, 우리는 적대적(= 잘못된) 클래스에 대한 뉴런의 최대 활성화를 찾습니다. 한 가지 차이점은 이미지입니다. 적대적 예제의 경우, 적대적 이미지를 생성하고자 하는 이미지입니다. 특성 시각화의 경우 접근 방식에 따라 무작위 노이즈입니다.
텍스트 및 표 형식의 데이터
이 글의 내용은 이미지 인식을 위한 컨볼루션 신경망의 특성 시각화에 초점을 맞추고 있습니다. 기술적으로, 표 형식의 데이터에 대해 완전히 연결된 신경망의 뉴런이나 텍스트 데이터를 위한 반복 신경망(Recurrent Neural Network)의 뉴런을 최대한 활성화시키는 입력을 찾는 것을 막을 수 있는 것은 없습니다. "특성"은 표 형식의 데이터 입력 또는 텍스트이므로 더 이상 특성 시각화라고 부르지 않을 수 있습니다. 신용부도 예측의 경우 입력은 이전 신용거래 수, 모바일 계약 수, 주소 및 기타 수십 가지 특성일 수 있습니다. 뉴런의 학습된 특성은 수십 가지의 특성의 특정한 조합일 것입니다. 반복 신경망의 경우, 네트워크가 학습한 내용을 시각화하는 것이 조금 더 좋습니다. Karpathy et al.(2015)는 반복 신경망에 실제로 해석 가능한 특성을 학습하는 뉴런이 있습니다는 것을 보여주었습니다. 그들은 이전 문자의 순서로 다음 문자를 예측하는 문자 수준 모델을 학습시켰습니다. 일단 여는 괄호 "("가 발생하자, 뉴런 중 하나가 매우 활성화되었고, 일치하는 닫는 괄호 ")"가 발생하면서 비활성화되었습니다. 다른 뉴런들은 선의 끝에서 활성화됩니다. 어떤 뉴런들은 URL로 활성화됩니다. CNN의 특성 시각화와 다른 점은 예시가 최적화를 통해 발견된 것이 아니라 학습 데이터에서 뉴런 활성화를 연구하여 발견되었다는 점입니다.
일부 이미지들은 개 주둥이나 건물과 같은 잘 알려진 개념을 보여주는 것 같습니다. 하지만 어떻게 확신할 수 있을까요? 신경망 해부 방법은 사람의 관념을 개별 신경망 단위와 연결합니다. 스포일러 경고: 신경망 해부를 수행하려면 누군가가 사람의 관점으로 분류한 추가 데이터셋이 필요합니다.
신경망 해부(Network Dissection)
Bau & Zhou et al.(2017)의 신경망 해부 접근법은 합성곱 신경망의 단위의 해석 가능성을 정량화합니다. CNN 채널의 고도로 활성화된 영역을 인간의 관념(객체, 파트, 텍스처, 색상 등)과 연결합니다.
합성곱 신경망의 채널은 특성 시각화에서 보았듯이 새로운 특성들을 학습합니다. 그러나 이러한 시각화는 하나의 단위가 특정 개념을 배웠다는 것을 증명하지 못합니다. 또한 하나의 단위가 마천루와 같은 것을 얼마나 잘 감지하는지 측정할 수 없습니다. 신경망 해부에 대한 세부 사항으로 들어가기 전에, 우리는 그 연구의 흐름 뒤에 있는 큰 가설에 대해 이야기해야만 합니다. 이 가설은 신경망의 단위(예: 합성곱 채널)가 분리된 개념(Disentangled Concepts)을 학습한다는 것입니다.
분리된 특성(Disentangled Feature)에 대한 질문
(합성곱) 신경망은 특정 영역에 여러 의미들이 얽히고 설켜있는 분리된 특성들을 학습할 수 있을까? 분리된 특성은 개별 신경망 단위가 특정 실제 개념을 탐지합니다는 것을 의미합니다. 합성곱 신경망의 394번째 채널은 초고층 빌딩을, 121번째 채널은 개의 주둥이를, 12번째 채널은 30도 각의 줄무늬로 탐지할 수 있을 겁니다. 분리된 신경망의 반대 개념은 완전히 얽힌 신경망입니다. 예를 들어, 완전히 얽힌 신경망에서는 개의 주둥이를 위한 개별 장치가 없습니다. 모든 채널은 개의 주둥이를 인식하는데 기여할 것입니다.
분리된 특성은 신경망이 매우 명료하게 물체를 해석할 수 있음을 의미합니다. 알려진 개념으로 레이블이 지정된 완전히 분리된 단위를 가진 신경망이 있다고 가정해 보겠습니다. 이렇게 하면 신경망의 의사 결정 프로세스를 추적할 수 있습니다. 예를 들어, 우리는 신경망이 늑대를 허스키와 어떻게 분류하는지를 분석할 수 있었다고 합시다. 먼저, "허스키" 단위를 확인합니다. 우리는 이 유닛이 이전 레이어의 "개의 주둥이", "푹신해보이는 털", "스노우" 단위에 의존하는지 확인할 수 있습니다. 만약 그렇다면, 우리는 그것이 눈 덮인 배경을 가진 허스키의 이미지를 늑대로 잘못 분류할 것이라는 것을 알고 있습니다. 분리된 신경망에서, 우리는 문제가 있는 채널간 인과관계없는 상관 관계를 식별할 수 있었을 것입니다. 우리는 개별 예측을 설명하기 위해 모든 고도로 활성화된 단위와 그 개념을 자동으로 나열할 수 있습니다. 우리는 신경망의 편향을 쉽게 감지할 수 있었을 겁니다. 예를 들어, 신경망은 급여를 예측하기 위해 "하얀 피부" 특성을 배웠을까요?
스포일러 경고: 합성곱 신경망은 특성들이 완전히 분리되지 않았습니다. 이제 우리는 신경망의 해석 가능 정도를 알아보기 위해 신경망 해부에 대해 좀 더 자세히 살펴볼 것입니다.
신경망 해부 알고리즘
신경망 해부는 다음과 같은 세 단계로 구성되어 있습니다.
- 사람의 관점에서 레이블된, 무늬에서부터 초고층 빌딩과 같은 이미지를 수집합니다.
- 수집된 이미지들을 위한 CNN 채널 활성화를 측정합니다.
- 활성화 및 레이블링된 개념의 정렬을 정량화합니다.
아래의 그림은 이미지가 채널로 전달되고 레이블이 지정된 개념과 일치되는 방식을 시각화합니다.

1단계: 브로든 데이터셋(Broden dataset)
첫 번째 단계로 어렵지만 중요한 단계는 데이터 수집입니다. 신경망 해부를 수행하려면 색상에서 거리 장면에 이르기까지 추상화 수준이 다른 개념의 픽셀 단위 레이블이 지정된 이미지가 필요합니다. Bau & Zou et. al의 데이터셋은 픽셀 단위 개념과 결합되었습니다. 그들은 이 새로운 데이터셋을 '브로든(Broden)'이라고 불렀는데, 이 데이터셋은 광범위하고 촘촘하게 레이블이 지정된 데이터를 의미합니다. 브로든 데이터셋은 대부분 픽셀 수준으로 분할되며 일부 데이터셋의 경우 전체 이미지에 레이블이 지정됩니다. 브로든 데이터셋은 다른 추상화 수준에서 1,000개 이상의 시각적 개념을 가진 60,000개의 이미지를 포함하고 있는데 468개의 장면(scene), 585개의 물체(Object), 234개의 파트(Part), 32개의 금속 물체(Material), 47개의 질감(Texture) 및 11개의 색(Color)으로 구성되어 있습니다. 아래 그림은 브로든 데이터셋의 샘플 이미지를 보여줍니다.

2단계: 신경망 활성화 탐색(Retrieve network activations)
다음 단계로 채널 및 이미지당 최상위 활성화 영역의 마스크를 생성합니다. 이 시점에서 개념 레이블은 아직 포함되지 않습니다.
- For 각 합성곱 채널 k:
- For 브로든 데이터샛 내의 각 이미지 x
- 이미지 x를 채널 k를 포함하는 목표층(Target layer)으로 전달.
- 합성곱 채널 k의 픽셀 활성화값 추출: \(A_k(x)\)
- 모든 이미지에 대해 픽셀 활성화값의 분산 \(\alpha_k\) 계산
- 활성화값 \(\alpha_k\)의 0.005 분위수 \(T_k\)를 결정. 이는 이미지 x에 대한 채널 k의 모든 활성화값의 0.5%가 \(T_k\)보다 크다는 의미.
- For 브로든 데이터셋 내의 각 이미지 x:
- (가능한) 저해상도 활성화 맵 \(A_k(x)\)의 크기를 이미지 x의 해상도로 조정. 이 결과를 \(S_k(x)\)라 칭함.
- Binarize the activation map: A pixel is either on or off, depending on whether it exceeds the activation threshold Tk. The new mask is .활성화 맵 이진화: 활성화 임계값 \(T_k\)를 초과하는지 여부에 따라 픽셀이 활성화되거나 비활성화됨. 새 마스크는 \(M_k(x)=S_k(x)\geq{}T_k(x)\).
- For 브로든 데이터샛 내의 각 이미지 x
3단계: 활성화 개념 정렬(Activation-concept alignment)
2단계 이후에는 채널 및 이미지당 하나의 활성화 마스크가 제공됩니다. 이러한 활성화 마스크는 활성화가 높은 영역을 표시합니다. 각 채널에 대해 우리는 그 채널을 활성화시키는 인간 개념을 찾고자 합니다. 활성화 마스크와 레이블이 지정된 모든 개념을 비교하여 개념을 찾습니다. 활성화 마스크 k와 개념 마스크 c 사이의 정렬을 IoU(Intersection over Union) 로 정량화합니다.
$$IoU_{k,c}=\frac{\sum|M_k(x)\bigcap{}L_c(x)|}{\sum|M_k(x)\bigcup{}L_c(x)|}$$
여기서 \(|\cdot|\)는 집합의 기수(Cardinality, 집합의 원소 갯수를 나타내는 수)입니다. IoU는 두 영역 간의 정렬을 비교합니다. \(IoU_{k,c}\)는 단위 k가 개념 c를 검출하는 정확도로 해석할 수 있습니다. \(IoU_{k,c}>0.04\)일 때, 단위 k를 개념 c의 검출기라 부릅니다. 이 한계값은 Bau & Zhou et. al.에 의해 선택되었습니다.
다음의 그림은 한 이미지에 대한 활성화 마스크와 개념 마스크 IoU를 설명합니다.

아래의 사진은 개를 감지한 단위에 대해 나타냅니다.

실험
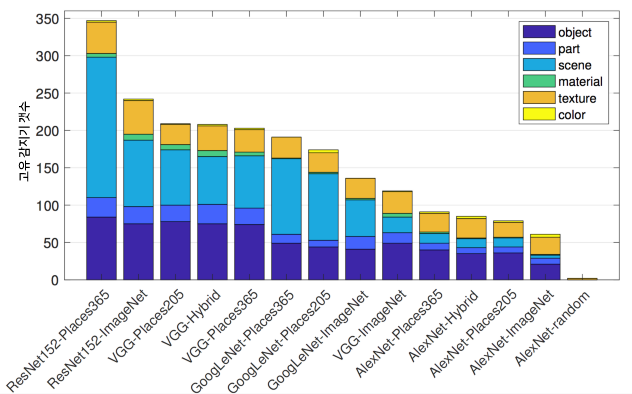
신경망 해부 저자는 서로 다른 데이터셋(ImageNet, Places205, Places365)에서 서로 다른 신경망 아키텍처(AlexNet, VGG, GoogleNet, ResNet)를 처음부터 학습시켰습니다. ImageNet에는 객체에 초점을 맞춘 1000개 클래스에서 160만 개의 이미지가 포함되어 있습니다. Place205 및 Places365에는 205/365개의 다른 장면에서 240만 개/160만 개의 영상이 포함됩니다. 그들은 비디오 프레임 순서를 예측하거나 이미지를 색칠하는 것과 같은 자기 지도학습 작업에 대해 AlexNet을 추가로 학습시켰습니다. 이러한 많은 다른 설정의 경우, 고유 개념 탐지기의 갯수를 해석력의 척도로 계산했습니다. 아래는 그것의 몇 가지 결과입니다.
- 신경망은 하위 계층에서는 하위 수준 개념(색상, 텍스처)을, 상위 계층에서는 상위 수준 개념(파트, 객체)을 탐지합니다. 이미 특성 시각화에서 이를 확인했습니다.
- 배치 일반화(Batch Normalization)은 고유 개념 탐지기의 갯수를 줄입니다.
- 많은 단위가 동일한 개념을 탐지합니다. 예를 들어 \(IoU \geq 0.04\)를 검출 컷오프(conv4_3에서 4개, conv5_3에서 91개, 프로젝트 웹사이트 참조)로 사용할 때 VGG에는 95개의 (!) 강아지 채널이 있습니다.
- 계층 채널 갯수를 증가시키는 것은 해석할 수 있는 단위의 수를 늘립니다.
- 무작위 초기화(다른 무작위 씨드를 사용한 학습)는 해석할 수 있는 단위의 갯수를 약간 다르게 만듭니다.
- ResNet은 가장 많은 수의 고유 감지기를 가진 신경망 아키텍처이며 VGG, GoogleNet 및 AlexNet이 그 뒤를 따릅니다.
- Places356에 대해 가장 많은 고유 개념 감지기가 학습되었고 Places205 및 ImageNet이 그 뒤를 따릅니다.
- 고유 개념 감지기의 수는 학습 반복 횟수에 따라 증가합니다.
- 자기지도학습으로 학습된 신경망은 지도학습으로 학습된 신경망에 비해 더 적은 수의 고유 감지기를 가지고 있습니다.
- 전이 학습에서 채널의 개념은 바뀔 수 있습니다. 예를 들어, 강아지 탐지기는 폭포 탐지기가 되기도 합니다. 이 문제는 처음에 객체를 분류하도록 훈련 받은 다음 장면을 분류하도록 미세 조정된 모델에서 발생했습니다.
- 실험 중 하나로서, 저자들은 채널을 새로운 순환 기준(Rotated basis)으로 예측했습니다. 이 작업은 ImageNet에서 학습된 VGG 신경망을 위해 수행되었습니다. 이때 "순환(Rotated)"는 이미지가 회전되었음을 의미하는 것은 아닙니다. "순환(Rotated)"은 conv5 레이어에서 256개의 채널을 가져와서 새로운 256개의 채널을 원래 채널의 선형 조합으로 계산한다는 의미입니다. 이 과정에서 채널이 꼬입니다. 순환은 해석력을 감소시킵니다. 즉, 개념과 정렬된 채널 수가 감소합니다. 순환은 모델의 성능을 동일하게 유지하도록 설계되었습니다. 첫 번째 결론은 다음과 같습니다. CNN의 해석력은 축에 따라 다릅니다. 즉, 임의의 채널 조합이 고유한 개념을 탐지할 가능성이 적다는 의미입니다. 두 번째 결론은 다음과 같습니다. 해석력은 판별력(Discriminate power)과 무관합니다. 판별력은 동일하지만 해석력은 감소하는 반면 채널은 직교 변환을 사용하여 변환할 수 있습니다.

저자들은 또한 GAN(Generative Adversarial Networks)을 위한 신경망 해부를 사용했습니다. 프로젝트의 웹 사이트에서 GAN용 신경망 섹션을 찾을 수 있습니다.
장점
특성 시각화는 특히 이미지 인식을 위해 신경망 동작에 대한 고유한 통찰력을 제공합니다. 신경망의 복잡성과 불투명성을 고려할 때, 특성 시각화는 신경망 분석 및 기술에서 중요한 단계입니다. 특성 시각화를 통해 신경망은 먼저 단순한 에지 및 텍스처 검출기와 더 높은 레이어에서 더 추상적인 부분 및 객체 검출기를 학습한다는 것을 알게 되었습니다. 신경망 해부는 이러한 통찰력을 확대하고 신경망 단위의 해석력을 측정할 수 있게 합니다.
신경망 해부를 통해 단위를 개념에 자동으로 연결할 수 있는데, 이는 매우 편리합니다.
특성 시각화는 신경망의 작동 방식을 비기술적으로 전달하는 훌륭한 도구입니다.
신경망 해부를 통해 분류 작업에서 클래스를 벗어난 개념도 감지할 수 있습니다. 그러나 픽셀 단위로 레이블이 지정된 이미지가 포함된 데이터셋이 필요합니다.
특성 시각화는 어떤 픽셀이 분류에 중요하게 적용되었는지 설명하는 특성 속성 방법과 결합될 수 있습니다. 두 방법의 조합은 분류에 포함된 학습된 특성의 지역 시각화와 함께 개별 분류를 설명할 수 있도록 합니다. jeffrew.pub 웹사이트의 해석력 블럭을 참조하세요.
마지막으로, 특성 시각화는 훌륭한 데스크탑 바탕화면 티셔츠 프린팅을 만듭니다.
단점
많은 특성 시각화 이미지는 전혀 해석할 수 없지만, 단어나 심적 개념이 없는 추상적인 특징을 포함하고 있습니다. 학습 데이터와 함께 특성 시각화를 표시하는 것이 도움이 될 수 있습니다. 이 이미지들은 여전히 신경망이 어떤 반응을 보였는지를 드러내지 않을 수 있고 "아마도 이미지에 노란색이 있을 것입니다"와 같은 것만을 보여줄 수 있습니다. 신경망 해부가 있더라도 일부 채널은 인간 개념에 연결되지 않습니다. 예를 들어 ImageNet에서 학습된 VGG의 layer conv5_3에는 인간 개념과 비교할 수 없는 193개의 채널(512개 채널 중 하나)이 있습니다.
채널 활성화"만" 시각화해도 볼 수 있는 단위가 너무 많습니다. Inception V1의 경우 이미 9개의 합성곱 계층에서 5000개 이상의 채널이 있습니다. 음의 활성화와 채널을 최대 또는 최소로 활성화하는 학습 데이터의 몇 가지 이미지(예: 양의 4개, 음의 4개)를 표시하려면 이미 50,000개 이상의 이미지를 표시해야 합니다. 적어도 우리는 신경망 해부 덕분에 임의의 방향을 조사할 필요가 없다는 것을 알고 있습니다.
해석력의 환상일까요? 특성 시각화는 우리가 신경망이 무엇을 하고 있는지 이해하고 있다는 환상을 전달할 수 있습니다. 하지만 우리는 정말로 신경망에서 무슨 일이 일어나고 있는지 이해할 수 있을까요? 수백 또는 수천 개의 특성 시각화를 살펴봐도 신경망을 이해할 수 없습니다. 채널들은 복잡한 방식으로 상호작용합니다. 양과 음의 활성화는 서로 관련이 없습니다. 여러 뉴런들이 매우 유사한 특성들을 배울 수 있고, 우리는 이와 동등한 인간 개념을 가지고 있지 않습니다. 단지 우리가 7번째 계층의 뉴런 349이 데이지꽃에 의해 활성화되는 것을 보았다고 해서 우리가 신경망을 완전히 이해했다고 믿는 함정에 빠져서는 안 됩니다. 신경망 해부는 ResNet 또는 Inception과 같은 아키텍처가 특정 개념에 반응하는 단위를 갖는다는 것을 보여주었습니다. 그러나 IoU는 그리 훌륭하지 않으며 많은 단위가 동일한 개념에 반응하고 일부는 아예 개념에 반응하지 않는 경우가 많습니다. 그 채널들이 완전히 분리되지 않았고 우리는 그것들을 따로 해석할 수 없습니다.
신경망 해부의 경우 픽셀 단계에서 개념 단위 레이블이 지정된 데이터셋이 필요합니다. 이러한 데이터셋은 각 픽셀에 레이블을 붙여야 하므로 수집에 많은 노력을 기울여야 하며, 일반적으로 이미지의 객체 주위에 세그먼트를 그립니다.
신경망 해부는 인간 개념을 양의 활성화에만 맞추지만 채널의 음의 활성화에는 맞추지 않습니다. 특성 시각화에서 알 수 있듯이, 음의 활성화는 개념과 연결되어 있는 것처럼 보입니다. 이 문제는 낮은 활성화 분위를 추가로 살펴봄으로써 해결할 수 있습니다.
소프트웨어 및 추가 자료
Lucid라고 불리는 오픈 소스로 구현된 특성 시각화 프로그램이 있습니다. Lucid Github 페이지에 제공되는 notebook 링크를 사용하여 브라우저에서 쉽게 사용할 수 있습니다. 추가 소프트웨어는 필요하지 않습니다. 다른 구현 소스코드로 TensorFlow로 구현된 tf_cnvis, Keras로 구현된 Keras Filters, Caffe로 구현된 DeepVis가 있습니다.
신경망 분해가 구현된 소프트웨어로는 훌륭한 프로젝트 웹 사이트가 있습니다. 논문 옆에 있는 웹사이트에는 코드, 데이터 및 활성화 마스크 시각화 같은 추가 자료가 마련되어 있습니다.
참고자료: https://christophm.github.io/interpretable-ml-book/cnn-features.html
7.1 Learned Features | Interpretable Machine Learning
Machine learning algorithms usually operate as black boxes and it is unclear how they derived a certain decision. This book is a guide for practitioners to make machine learning decisions interpretable.
christophm.github.io
'해석할 수 있는 기계학습 > 7. 신경망 해석' 카테고리의 다른 글
| [해석할 수 있는 기계학습(7-3)] 개념 탐지(Detecting Concepts) (0) | 2021.08.30 |
|---|---|
| [해석할 수 있는 기계학습(7-2)]픽셀 속성 - Pixel Attribution(중요영역 지도 - Saliency Maps) (0) | 2021.07.12 |
| [해석할 수 있는 기계학습(7-0)]신경망 해석(Neural Network Interpretation) (0) | 2021.05.17 |


