
늦깎이 공대생의 인공지능 연구실
[MLOps] 고급 레이블링, 데이터 증강 및 데이터 전처리(1) 본문
※이 자료는 Deeplearning.ai에서 제공하는 MLOps의 자료를 인용하였습니다.
MLOps란 단순히 기계학습 모델 뿐 아니라, 데이터를 수집하고 분석하는 단계 (Data Collection, Ingestion, Analysis, Labeling, Validation, Preparation), 그리고 기계학습 모델을 학습하고 배포하는 단계(Model Training, Validation, Deployment)까지 전 과정을 AI Lifecycle로 보고 이에 대한 전반적인 내용을 이해하는 것을 목적으로 합니다.
지금부터 다루고자 하는 내용들은 MLOps 과정 중 생산 전문화를 위한 기계학습 데이터 Lifecycle의 방법들 중 일부인 고급 레이블링(Advanced labeling), 데이터 증강(Data augmentation), 데이터 전처리(Data preprocessing)에 대한 내용입니다.
준지도학습(Semi-supervision)
고급 레이블링이 중요한 이유

먼저 중요한 질문부터 드리겠습니다. 각 예제를 수동으로 입력하지 않고 어떻게 Label을 할당할 수 있을까요? 다시 말해, Labeling 과정에서 부정확성을 발생시키는 비용을 감수하고라도 공정을 자동화할 수 있을까요?
본 내용은 고급 레이블링에 대한 내용을 다루고자 합니다.
이 과정의 첫 번째 단계는 준지도(Semi-supervised) 레이블링의 동작 방식과 레이블링된 데이터셋을 확장하여 모델 성능을 향상시키는 방법에 대해 살펴보는 것입니다. 다음 단계는 능동 학습(Active learning)으로, 지능형 샘플링을 사용하여 기존 데이터를 기반으로 레이블이 지정되지 않은 데이터에 레이블을 할당합니다. 마지막 단계는 약한 지도(Weak supervision)로, 주제 전문가(Subject matter experts)가 설계한 휴리스틱(Heuristic)을 사용하여 데이터에 프로그래밍 방식으로 Label을 붙이는 방법입니다. 스노클(Snorkel)이 약한 지도를 적용하기 위한 친근한 프레임워크입니다.
고급 Labeling은 왜 중요한가요? 기계학습은 모든 곳에서 성장하고 있고 머신러닝은 최소한 지도 학습을 할 경우 학습 데이터, Label된 데이터가 필요합니다. 이는 우리에게 Label을 붙인 학습 데이터셋이 필요하다는 의미입니다. 그러나 수동으로 데이터에 Label을 지정하는 것은 종종 비용이 많이 들고 어려운 반면 레이블링되지 않은 데이터는 일반적으로 상당히 저렴하고 쉽게 구할 수 있습니다. Label이 없는 데이터에는 모델을 개선하는 데 도움이 되는 많은 정보가 포함되어 있습니다. 고급 Labeling 기술은 레이블링되지 않은 대량의 데이터에서 정보를 활용하면서 데이터 레이블링 비용을 절감하는 데 도움이 됩니다.

준지도(Semi-supervised) 레이블링을 사용하면 사람이 레이블이 적용된 비교적 작은 데이터셋에서부터 시작할 수 있습니다. 그런 다음, 레이블이 지정된 데이터와 레이블이 지정되지 않은 대량의 데이터를 결합합니다. 이 때 특성 공간 내에 있는 클러스터되거나 구조화되어 사람에 의해 레이블링된 클래스와의 차이를 비교함으로서 구조화되지 않은 데이터의 레이블을 추론할 수 있습니다.
이제 두 데이터셋을 조합하여 모델을 학습시킵니다. 이 방법은 서로 다른 레이블 클래스가 함께 클러스터링되거나 특성 공간 내에 인식할 수 있는 구조가 있다는 가정을 기반으로 합니다.
준지도 레이블링을 사용하는 이점은 두 가지가 있습니다.
- 레이블링된 데이터와 레이블링되지 않은 데이터를 결합하면 머신러닝 모델의 정확도를 향상시킬 수 있습니다.
- 레이블이 없는 데이터를 얻는 것은 사람이 직접 레이블을 할당할 수고가 없기 때문에 종종 매우 저렴합니다. 레이블이 없는 데이터는 대량으로 쉽게 구할 수 있습니다.
레이블 전파(Label propagation)는 이전에 레이블이 지정되지 않은 예제에 레이블을 할당하는 알고리즘입니다. 따라서 데이터 포인트의 하위 집합에 레이블이 있는 준지도 알고리즘이 됩니다. 알고리즘은 레이블을 레이블 없이 데이터 포인트로 전파합니다. 이는 레이블이 지정된 데이터 포인트과 레이블이 지정되지 않은 데이터 포인트의 유사성 또는 군집 구조를 기반으로 합니다. 이 유사성 또는 구조는 레이블이 지정되지 않은 데이터에 레이블을 할당하는 데 사용됩니다.

예를 들어, 위의 그림과 같이 그래프 기반 데이터가 있을 때, 이 그림에서 빨간색, 파란색, 녹색 삼각형과 회색 원으로 레이블이 지정되지 않은 많은 데이터를 볼 수 있습니다. 이 방법을 사용하면 인접 예제에 따라 레이블이 지정되지 않은 예제에 레이블을 할당합니다. 그런 다음 레이블은 색상별로 표시된 대로 나머지 군집으로 전파됩니다.
레이블 전파를 할 수 있는 다양한 방법이 있습니다. 그래프 기반 레이블 전파는 여러 기술 중 하나에 불과합니다. 레이블 전파 자체는 변환 학습(Transductive learning)으로 간주되는데, 이는 우리가 매핑에 대한 함수를 배우지 않고 예제 자체로부터 매핑하고 있다는 것을 의미합니다.
능동학습(Active learning)
능동학습은 데이터를 지능적으로 샘플링하는 방법입니다. 지능형 샘플링은 모델에 가장 예측 가능한 값을 유도할 수 있는 레이블이 지정되지 않은 포인트(Unlabeled point)를 선택합니다. 이는 다양한 상황에서 매우 유용합니다. 무엇보다도, 데이터 예산에 제한이 있을 때 유용합니다. 이는 데이터에 레이블을 붙이는 비용을 유발하는데, 예를 들어 특히 의료 분야에서 데이터를 살펴보고 레이블을 할당할 때 능동학습이 이러한 비용과 부담을 상쇄하는 데 도움이 될 수 있습니다. 불균형 데이터셋이 있는 경우 능동학습이 학습 단계에서 희귀한 클래스를 선택하는 효율적인 방법입니다. 표준 샘플링 기술이 정확도 및 기타 목표값을 개선하는 데 도움이 되지 않는다면 능동학습은 원하는 정확도를 달성하거나 달성할 수 있는 방법을 찾을 수 있습니다.
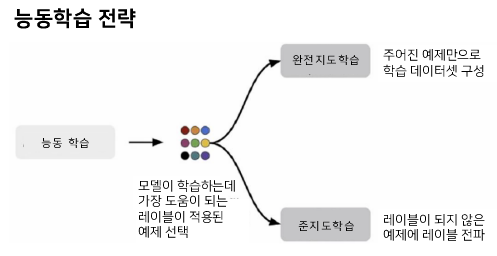
능동학습 전략은 모델이 학습하는 데 가장 도움이 되는 레이블이 적용된 예제를 선택하여 동작합니다. 완전 지도학습 설정에서 학습 데이터셋은 레이블이 지정된 예제로만 구성됩니다. 준지도학습 설정에서는 이러한 예제를 활용하여 레이블 전파를 수행하므로 능동학습 외에도 이를 수행할 수 있습니다.
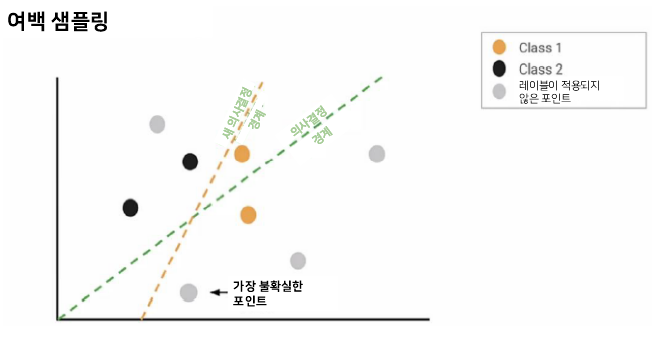
여백 샘플링(Margin sampling)은 지능형 샘플링을 수행하는 데 널리 사용되는 기술 중 하나입니다. 이 예제에서 데이터는 각각 두 개의 클래스 중 하나에 속하며 레이블이 없는 데이터 포인트도 있습니다. 이 설정에서 가장 간단한 전략은 단순하게 만드는 이진 선형 분류기 모델을 학습시키는 것입니다. 우리는 선형 모델만을 예로 들겠습니다. 모델을 라벨이 붙은 데이터로 훈련시킬 것이고, 이 모델은 우리에게 의사결정 경계를 나타낼 것입니다. 레이블이 없는 데이터 중에서 가장 불확실한 데이터 포인트는 의사결정 경계에 가장 가까운 점입니다. 능동학습을 통해 다음에 레이블을 지정하여 데이터셋에 추가할 가장 불확실한 포인트를 선택할 수 있습니다. 이제 이 새로운 레이블링된 데이터 포인트를 데이터셋의 일부로 사용하여 모델을 재교육하여 새로운 분류 경계를 학습합니다. 경계를 이동하면 모델은 이러한 클래스를 분리하는 방법을 조금 더 잘 학습합니다. 그런 다음 가장 불확실한 데이터 포인트를 다시 찾고 모델이 개선되지 않을 때까지 프로세스를 반복합니다.

약한 지도(Weak supervision)
약한 지도 하나 이상의 출처 정보를 사용하여 레이블을 생성하는 방법입니다. 보통 이들은 주제 전문가들(Subject matter experts) 입니다. 그리고 이들은 주로 휴리스틱 알고리즘을 설계합니다. 결과 레이블(Resulting label)은 우리가 익숙한 결정론적 레이블(Deterministic label)보다는 노이즈(잡음)가 많습니다. 보다 구체적으로 약한 지도는 레이블이 지정되지 않은 데이터에 대해 하나 이상의 노이즈가 있는 조건부 분포를 포함합니다. 주된 목적은 이러한 노이즈 발생원의 관련성을 결정하는 생성 모델을 배우는 것입니다.
따라서, 레이블이 지정되지 않은 데이터부터 시작하기 때문에 실제 레이블을 알 수 없습니다. 그 다음 하나 이상의 약한 지도 출저를 혼합하여 추가합니다. 이러한 출저는 노이즈가 많고 불완전한 자동 레이블링을 구현하는 휴리스틱 접근 절차 방법들의 리스트입니다. 주제 전문가는 일반적으로 탐지 범위 세트와 탐지 범위 세트에 대한 실제 레이블의 예상 확률로 구성된 이러한 휴리스틱을 설계하는 가장 일반적인 출처입니다. 결정론적 레이블 대신 휴리스틱 또는 레이블링 함수를 사용합니다. 노이즈가 있다는 것은 레이블이 레이블링된 데이터의 레이블에 대해 사용되었던 100개의 확실성이 아닌 특정 확률을 가지고 있음을 의미합니다. 주요 목표는 각 지도 출저의 신뢰도를 배우는 것이며, 이는 생성 모델을 학습시킴으로써 이루어집니다. 전반적으로 해당 분야 전문가의 의견을 활용하고 프로그래밍을 통해 학습 데이터셋을 만들고 구조화합니다.
스노클(Snorkel)
스노클(Snorkel) 프레임워크는 2016년에 스탠포드에서 만들어졌으며 약한 지도를 구현하기 위해 가장 널리 사용되는 프레임워크입니다. 수동 레이블링이 필요하지 않아 시스템에서 학습 데이터셋을 프로그래밍 방식으로 구축하고 관리합니다. 스노클은 약한 지도 파이프라인을 통해 상승하는 결과적인 학습 데이터를 명료화, 모델링, 통합을 위한 도구를 제공합니다. 스노클은 작업을 신속하고 효율적으로 수행하기 위해 이론적으로 기초가 된 새로운 기술을 사용합니다. 또한 스노클은 데이터 증강 및 슬라이싱 기능도 제공합니다.

스노클을 사용하면 레이블링되지 않은 데이터와 함께 시작하여 레이블링 함수를 적용할 수 있습니다. 이는 주제 전문가들이 노이즈가 많은 레이블을 만들기 위해 고안한 휴리스틱입니다. 그 다음 생성 모델을 사용하여 노이즈를 제거하고 중요도 가중치를 여러 레이블 함수에 할당합니다. 즉, 관리 출저에 대한 가중치를 결정합니다. 마지막으로 노이즈가 제거된 레이블을 사용하여 분류 모델, 즉 모델을 학습시킵니다.

이번에는 간단한 레이블링 함수 몇 가지를 코드에서 살펴보겠습니다. 여기서는 스노클을 이용하여 스팸에 레이블을 붙이는 함수를 간단하게 만드는 방법을 보여드리겠습니다. 첫 단계는 스노클에서 레이블벨링 함수를 가져오는 것입니다. 그리고 이 함수의 레이블링으로 만약 'my'라는 단어가 포함되어 있다면 스팸 메시지를 보냅니다. 이는 보여주기 쉬운 예제이므로 'my'가 있는 메시지는 스팸일 필요가 없습니다. 그렇지 않으면 함수가 기권되어 반환되며, 이는 레이블이 무엇이어야 하는지에 대한 의견이 없음을 의미합니다. 두 번째 함수는 메시지 스팸이 5단어보다 길 경우 레이블을 지정합니다. 그래서 여기서 보이고자 하는 것은 레이블이 어떻게 되어야 하는지에 대한 결론에 도달하기 위해 여러 가지 레이블링 함수를 사용하고 있었다는 것입니다.
지도학습에는 레이블이 지정된 데이터가 필요하지만 데이터에 레이블을 지정하는 것은 종종 비용이 많이 들고 어렵고 느린 방법입니다. 준지도학습은 레이블이 지정되지 않은 데이터에 레이블을 추가하는 한 가지 방법입니다. 그래서 이 방법은 비지도 학습과 지도 학습 사이에 있는 방법입니다. 이는 적은 양의 레이블링된 데이터와 레이블링되지 않은 많은 양의 데이터를 결합함으로써 학습 정확도를 향상시킵니다. 능동학습은 또 다른 고급 레이블링 방법입니다. 데이터셋에 레이블을 지정하고 추가할 가장 중요한 예제를 선택하는 지능형 샘플링 기술에 의존합니다. 능동학습은 레이블링 비용을 최소화하면서 예측 정확도를 향상시킵니다. 마지막으로 약한 지도는 감독된 학습 환경 내에서 노이즈가 많거나 제한적이거나 부정확한 레이블 출저를 활용하여 레이블링 정확도를 테스트합니다. 스노클은 약한 지도를 위해 이러한 모든 작업을 관리하고 약한 지도를 사용하여 학습 데이터셋을 설정하는 간편하고 사용자 친화적인 시스템입니다.
데이터 증강(Data augmentation)

지금까지 레이블이 지정되지 않은 데이터에 레이블을 지정하여 더 많은 레이블이 지정된 데이터를 가져오는 방법을 살펴보았습니다. 그러나 또 다른 방법은 레이블이 지정된 예제를 만들기 위해 기존 데이터를 증강시키는 것입니다. 데이터 증강을 통해 기존 데이터의 약간 수정된 복사본을 추가하여 데이터셋을 확장하거나 기존 데이터에서 새로운 합성 데이터를 생성할 수 있습니다. 기존 데이터를 사용하면 기존 샘플에서 사소한 변경이나 교란을 통해 더 많은 데이터를 만들 수 있습니다. 뒤집기 또는 회전 같은 간단한 작업은 데이터셋의 이미지 수를 두 배 또는 세 배로 늘릴 수 있는 쉬운 방법입니다.

데이터 증강은 모델의 성능을 향상시키고, 실제 예제에서 다루지 않는 특성 공간의 영역에 해당하는 유효한 새 예제를 추가하고, 유효한 예제를 추가하는 방법으로 특성 공간의 적용 범위를 향상시킬 수 있습니다. 잘못된 예제를 추가할 경우 잘못된 답을 학습하거나 최소한 원치 않는 노이즈가 발생할 위험이 있습니다. 따라서 유효한 방법으로만 데이터를 늘려야 합니다.

CIFAR는 캐나다 고등연구기관입니다. CIFAR-10 데이터셋은 기계 학습 모델과 컴퓨터 비전 모델을 학습시키는 데 일반적으로 사용되는 이미지 모음입니다. 머신러닝 연구에 가장 널리 사용되는 데이터셋 중 하나입니다. CIFAR-10에는 60,000개의 32 x 32 사이즈 컬러 이미지가 포함되어 있습니다. 각 클래스마다 6000개의 이미지를 가진 10개의 클래스가 있습니다.
CIFAR-10 데이터셋을 사용한 데이터 증강에 대해 살펴보겠습니다. 테두리에 여백을 둔 패딩 이미지를 추가하고 패딩된 이미지를 32x32 이미지로 자른 후 동전 던지기 또는 랜덤 변수를 기준으로 패딩 혹은 자른 이미지를 뒤집거나 회전합니다. 이는 모델이 특정 회전 또는 크기에 과적합되지 않도록 하기 위함입니다.

컬러 이미지는 텐서이기 때문에 Tensorflow는 이미지 데이터셋에서 데이터 증강을 수행하는 데 매우 유용한 함수를 제공합니다. 왼쪽, 오른쪽 플립을 수행하는 단계를 캡슐화한 코드 덩어리를 살펴보겠습니다. 먼저 이미지 데이터셋을 증강시키는데 사용할 함수를 정의합니다. 그런 다음 이미지 크기를 조정하거나 자를 수 있는 crop_or_pad와 함께 tf.image.size를 사용합니다. 이 경우 pad를 적용하겠습니다. tf.image.random 자르기는 모든 채널에서 가로세로 높이의 자르기를 생성합니다. 그리고 tf.image.random을 왼쪽으로, 오른쪽으로 뒤집으면 왼쪽이나 오른쪽으로 뒤집는 것과 같은 동작을 합니다. 따라서 이 함수는 데이터셋에 추가할 변경된 이미지를 리턴합니다.

위 그림은 패딩, 크롭, 왼쪽, 오른쪽 플립 후 예제입니다.
단순한 이미지 조작 외에도 비지도 데이터 증강 또는 UDA와 같은 준지도 데이터 증강과 같은 다른 고급 데이터 증강 기술이 있습니다. 그리고 정책 증강을 통해 변형된 예제를 생성합니다. 이제 우리는 증강을 통해 완벽하게 유효한 새로운 예시를 만들 수 있습니다. 우리는 이를을 다시 수행할 수 있고, 또 다른 것을 생성할 수 있습니다.
※ 다음 포스팅에서 내용이 이어집니다.
참고자료: https://ko.coursera.org/learn/machine-learning-data-lifecycle-in-production
Machine Learning Data Lifecycle in Production
deeplearning.ai에서 제공합니다. In the second course of Machine Learning Engineering for Production Specialization, you will build data pipelines by ... 무료로 등록하십시오.
ko.coursera.org
'AI기술설명' 카테고리의 다른 글
| AI로 추상화 그리기: DALL-E 2 vs Midjourney vs StableDiffusion (0) | 2022.08.31 |
|---|---|
| [MLOps] 고급 레이블링, 데이터 증강 및 데이터 전처리(2) (0) | 2022.03.11 |
| ICML Tutorial on Model-Based Methods in Reinforcement Learning(모델 기반 강화학습) - 1.소개 및 모델 학습 (0) | 2022.02.03 |
| YOLO로 이해하는 이미지 객체 감지(2) - YOLO의 역사 (1) | 2021.10.31 |
| YOLO로 이해하는 이미지 객체 감지(1) - Object Detection (0) | 2021.09.24 |



