
늦깎이 공대생의 인공지능 연구실
[논문프리뷰] Visual Haystacks: 이미지셋에 대한 어려운 질문에 답하기(Are We Ready for Multi-Image Reasoning? Launching VHs: The Visual Haystacks Benchmark!) 본문
[논문프리뷰] Visual Haystacks: 이미지셋에 대한 어려운 질문에 답하기(Are We Ready for Multi-Image Reasoning? Launching VHs: The Visual Haystacks Benchmark!)
Justin T. 2024. 7. 31. 23:57인간은 방대한 시각 자료 처리에 탁월하며, 이는 인공 일반 지능(AGI)을 구현하는 데 매우 중요한 기술입니다. 수십 년 동안 AI 연구자들은 단일 이미지 내의 장면을 해석하고 관련 질문에 답하는 VQA(Visual Question Answering) 시스템을 개발해 왔습니다. 최근 기초 모델의 발전으로 인간과 기계의 시각 처리 사이의 격차가 크게 좁혀졌지만, 기존의 VQA는 전체 시각 데이터 집합보다 한 번에 단 하나의 이미지에 대해서만 추론하는 것으로 제한되어 왔습니다.
이러한 한계는 보다 복잡한 시나리오에서 문제가 발생합니다. 예를 들어 의료 이미지 자료에서 패턴을 식별하거나, 위성 이미지를 통해 삼림 벌채를 모니터링하거나, 자율 주행 데이터를 사용하여 도심 변화를 매핑하거나, 대규모 미술품 컬렉션에서 주제별 요소를 분석하거나, 매장 감시 영상에서 소비자 행동을 이해하는 등의 문제를 생각해 볼 수 있습니다. 이러한 각 시나리오에는 수백, 수천 개의 이미지에 대한 시각적 처리뿐 아니라 이러한 결과의 이미지 상호 간 처리도 필요합니다. 이 격차를 해소하기 위해 이 프로젝트에서는 기존 VQA 시스템의 범위를 뛰어넘는 “ MIQA( Multi Image Question Answering)” 작업에 초점을 맞춘 프로젝트입니다.

어떻게 MIQA에서 VQA 모델을 벤치마킹하는가?
NIAH(Needle-In-A-Haystack) 작업(건초 더미 속에서 바늘 찾기)은 최근 “긴 컨텍스트”, 대량의 입력 정보(긴 문서, 동영상 또는 수백 개의 이미지 등)가 포함된 입력 데이터를 처리하는 LLM의 능력을 벤치마킹하기 위한 가장 인기 있는 패러다임 중 하나로 자리 잡았습니다. 이 작업에서는 특정 질문에 대한 답을 담고 있는 필수 정보(“바늘”)가 방대한 양의 데이터(“건초 더미”) 속에 포함되어 있습니다. 이러한 작업이 완료되면 시스템은 관련 정보를 검색하여 질문에 올바르게 답해야 합니다.
시각적 추론에 대한 최초의 NIAH 벤치마크는 Google이 Gemini-v1.5 기술 보고서에서 소개되었습니다. 이 보고서에서는 모델에 대용량 동영상의 단일 프레임에 겹쳐진 텍스트를 검색하도록 요청했습니다. 기존 모델이 이 작업을 꽤 잘 수행하는 것으로 나타났는데, 이는 강력한 OCR 검색 기능 덕분이었습니다. 하지만 좀 더 시각적인 질문을 하면 어떨까요? 과연 모델이 여전히 잘 작동할까요?
Visual Haystacks(VHs) 벤치마크란?
“시각 중심”의 긴 문맥 추론 능력을 평가하기 위해 “시각적 헤이스택(VH)” 벤치마크를 소개합니다. 이 새로운 벤치마크는 상호 연관성이 없는 대규모 이미지셋에 대한 시각적 검색 및 추론에서 대규모 다중 모드 모델(Large Multimodal Models, LMM)을 평가하기 위해 개발되었습니다. VH는 약 1,000개의 이진 질문-답변 쌍으로 구성되며, 각 세트에는 1~10,000개의 이미지가 포함되어 있습니다. 텍스트 검색 및 추론에 중점을 둔 이전 벤치마크와 달리, VH의 질문은 COCO 데이터셋의 이미지와 주석을 활용하여 사물과 같은 특정 시각적 내용의 존재를 식별하는 데 중점을 둡니다.
VH 벤치마크는 쿼리에 응답하기 전에 관련 이미지를 정확하게 찾고 분석하는 모델의 능력을 테스트하기 위해 설계된 두 가지 주요 문제들로 나뉩니다. 우리는 이미지를 보지 않고 추측하거나 상식적인 추론에만 의존하는 경우 아무런 이점도 얻지 못하도록 데이터셋을 신중하게 구성했습니다(예: 이진 QA 작업에서 50%의 정확도 결과).
- Single-Needle Challenge: 건초 더미처럼 쌓인 이미지에는 단 하나의 이미지만 존재합니다. “앵커 객체가 있는 이미지에 대상 객체가 있는가?”라는 질문으로 질문의 틀을 구성합니다.
- Multi-Needle Challenge: 이미지 더미에는 2~5개의 이미지가 존재합니다. “앵커 객체가 있는 모든 이미지에, 목표 객체가 포함되어 있는가?” 또는 “앵커 객체가 있는 모든 이미지 중 목표 객체가 하나라도 포함되어 있는가?” 와 같은 질문으로 구성됩니다.
VH에서 얻은 세 가지 중요한 결과
Visual Haystacks(VH) 벤치마크는 광범위한 시각적 입력을 처리할 때 현재 대규모 멀티모달 모델(Large Multimodal Models, LMM)이 직면하는 중요한 문제점을 드러냅니다. Single 및 Multi-Needle 모드에 대한 실험1에서는 LLaVA-v1.5, GPT-4o, Claude-3 Opus, Gemini-v1.5-pro 등 여러 오픈 소스 및 자체 개발 방법을 평가했습니다. 또한 '캡션' 기준을 포함시켜 처음에 LLaVA를 사용하여 이미지를 캡션한 다음, 캡션의 텍스트 콘텐츠를 사용하여 질문에 답하는 2단계 접근 방식을 사용했습니다(Llama3). 아래는 세 가지 중요한 시사점을 제시합니다:
1. 시각적 방해 요소로 인한 어려움
Single-needle 설정에서는 높은 오라클 정확도를 유지함에도 불구하고 이미지 수가 증가함에 따라 눈에 띄는 성능 저하가 관찰되었는데, 이는 이전의 텍스트 기반 Gemini-스타일 벤치마크에서는 볼 수 없었던 시나리오입니다. 이는 기존 모델이 특히 시각적 방해 요소가 있는 경우 시각적 검색에 어려움을 겪을 수 있음을 보여줍니다. 또한, 2K 컨텍스트 길이 제한으로 인해 최대 3개의 이미지만 처리할 수 있는 LLaVA와 같은 오픈 소스 LMM의 제약을 강조하는 것이 중요합니다. 반면에 Gemini-v1.5 및 GPT-4o와 같은 독점 모델은 확장된 컨텍스트 기능을 제공한다고 주장하지만 API 호출 시 페이로드 크기 제한으로 인해 이미지 수가 1K를 초과하는 경우 요청을 관리하지 못하는 경우가 많습니다.

2. 여러 이미지에 걸쳐 추론하기 어려움
흥미롭게도 모든 LMM 기반 방법은 캡션 모델(LLaVA)과 LLM 수집기(Llama3)를 연결하는 기본 접근 방식에 비해 단일 이미지 QA 및 모든 Multi-needle 설정에서 5개 이상의 이미지에서 약한 성능을 보였습니다. 이러한 차이는 LLM이 긴 문맥의 캡션을 효과적으로 통합할 수 있는 반면, 기존 LMM 기반 솔루션은 여러 이미지에서 정보를 처리하고 통합하는 데 부적합하다는 것을 시사합니다. 특히 다중 이미지 시나리오에서는 성능이 크게 저하되는데, Claude-3 Opus는 오라클 이미지만 있는 경우 약한 결과를 보이고, Gemini-1.5/GPT-4o는 50개의 이미지로 구성된 대규모셋에서는 50%의 정확도(무작위 추측과 같은)로 떨어지는 것으로 나타났습니다.

3. 시각적 영역에서의 현상
마지막으로, LMM의 정확도는 입력 시퀀스 내 질문의 이미지의 위치에 따라 크게 영향을 받는다는 사실을 발견했습니다. 예를 들어, LLaVA는 질문 바로 앞에 해당 이미지가 배치될 때 더 나은 성능을 보였으며, 그렇지 않은 경우 최대 26.5%의 성능 저하를 보였습니다. 반면, 독점 모델은 일반적으로 이미지가 시작 부분에 위치할 때 더 나은 성능을 보이며 그렇지 않을 경우 최대 28.5%의 성능 저하를 경험합니다. 이 패턴은 문맥의 시작이나 끝에 위치한 중요한 정보가 모델 성능에 영향을 미치는 자연어 처리(NLP) 분야에서 볼 수 있는 ''중간 손실(lost-in-the-middle)" 현상을 반영합니다. 이 문제는 텍스트 검색과 추론만 요구했던 이전 Gemini-스타일의 NIAH 평가에서는 분명하지 않았으며, 이는 VH 벤치마크가 가진 고유한 도전 과제를 보여 줍니다.

MIRAGE: VH 성능 향상을 위한 RAG 기반 솔루션
위의 실험 결과에 따르면 기존 MIQA 솔루션의 핵심 난제는 (1) 관련성이 없는 방대한 이미지 더미에서 위치 편향 없이 관련 이미지를 정확하게 검색하고 (2) 이러한 이미지에서 관련 시각 정보를 통합하여 질문에 정확하게 답하는 능력에 있다는 것을 알 수 있습니다. 이러한 문제를 해결하기 위해 우리는 오픈 소스의 간단한 단일 단계 훈련 패러다임인 “MIRAGE”(Multi-Image Retrieval Augmented Generation)를 도입하여 LLaVA 모델을 확장하여 MIQA 작업을 처리합니다. 아래 이미지는 모델 아키텍처를 나타냅니다.
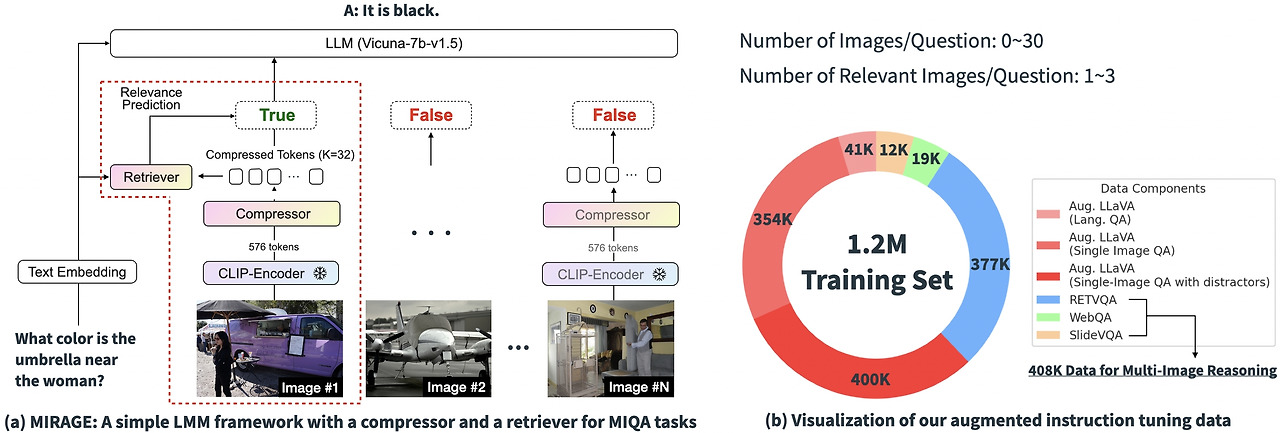
- 기존 인코딩 압축: MIRAGE 패러다임은 쿼리 인식 압축 모델을 활용하여 시각적 인코더 토큰을 10배 더 작은 하위 집합으로 줄여 동일한 컨텍스트 길이에 더 많은 이미지를 저장할 수 있도록 합니다.
- 연관 없는 메시지를 걸러내기 위한 검색 기능을 활용: MIRAGE는 LLM 미세 조정을 통해 훈련된 검색 기능을 사용하여 이미지가 관련성이 있는지 예측하고 관련성이 없는 이미지를 동적으로 삭제합니다.
- 멀티 이미지 학습 데이터: MIRAGE는 기존의 단일 이미지 명령어 미세 조정 데이터를 다중 이미지 추론 데이터 및 합성 다중 이미지 추론 데이터로 보강합니다.
결과
MIRAGE를 통해 VH 벤치마크를 다시 살펴봅니다. 1천 개 또는 1만 개 이미지를 처리할 수 있을 뿐 아니라, 이미지당 토큰 수가 32개에 불과한 약한 단일 이미지 QA 백본에도 불구하고 대부분의 Single-needle 작업에서 MIRAGE는 최첨단 성능을 달성합니다!
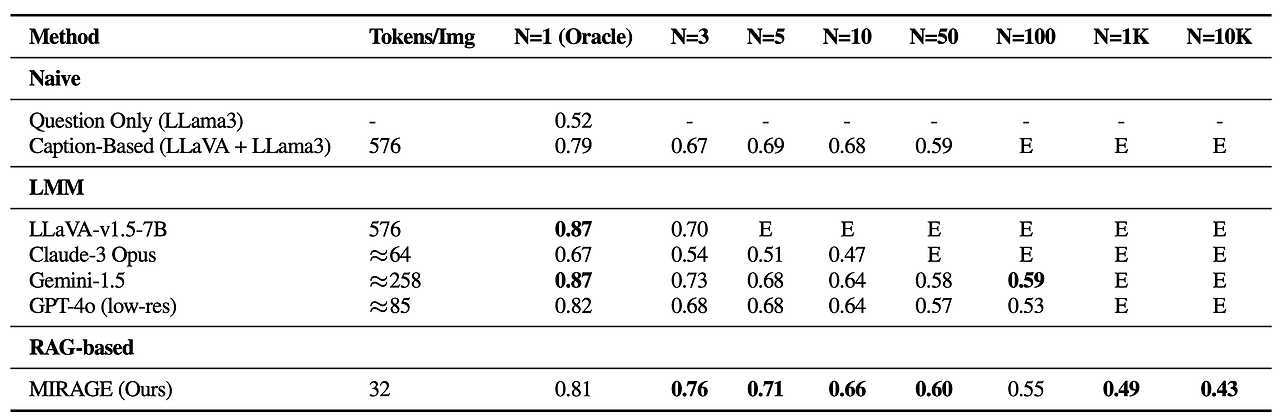
또한 다양한 VQA 작업에서 MIRAGE 및 기타 LMM 기반 모델을 벤치마킹합니다. 다중 이미지 작업에서 MIRAGE는 강력한 재현율(Recall)과 정밀도(Precision)를 보여주며 GPT-4, Gemini-v1.5, LWM(Large World Model)과 같은 강력한 경쟁 모델보다 훨씬 뛰어난 성능을 발휘합니다. 뿐만 아니라 경쟁력 있는 단일 이미지 QA 성능도 보여줍니다.
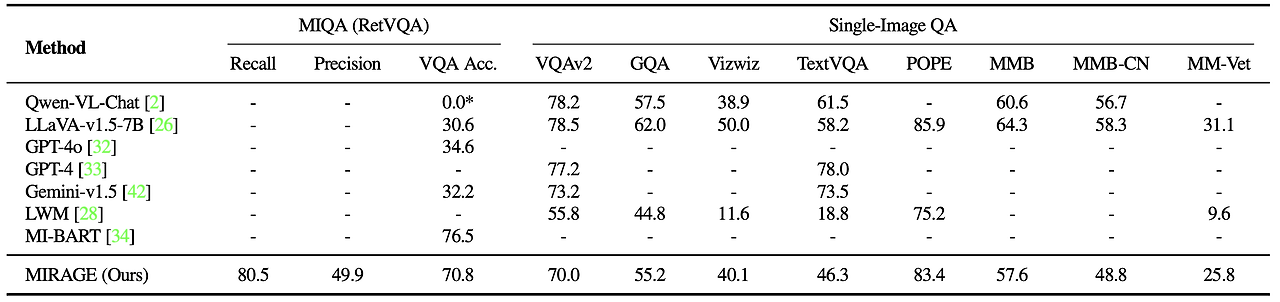
마지막으로, MIRAGE의 함께 훈련된 검색 기능을 CLIP과 비교했습니다. MIRAGE의 검색 기능은 효율성을 잃지 않으면서도 CLIP보다 훨씬 뛰어난 성능을 발휘합니다. 이는 CLIP 모델이 개방형 어휘 이미지 검색에는 좋은 검색 기능일 수 있지만, 질문과 같은 텍스트를 처리할 때는 잘 작동하지 않을 수 있음을 나타냅니다
최종 의견
이 연구에서는 Visual Haystacks(VHs) 벤치마크를 개발하여 기존 대형 멀티모달 모델(Large Multimodal Model, LMM)에서 가장 널리 알려진 세 가지 단점을 파악했습니다:
- 시각적 방해 요소와의 대결: LMM에서는 Single-needle 작업에서 이미지 수가 증가함에 따라 성능이 급격히 저하되어 관련 없는 시각 정보를 걸러내는 데 상당한 어려움이 발생합니다.
- 여러 이미지에 걸친 추론의 어려움: Mult-needle 설정에서는 캡션과 언어 기반 QA와 같은 단순한 접근 방식이 기존의 모든 LMM보다 성능이 떨어지며, 이는 여러 이미지에 걸쳐 정보를 처리하는 LMM의 부족한 성능을 강조합니다.
- 시각 영역에서의 현상: 독점 모델과 오픈 소스 모델 모두 이미지 시퀀스 내 필요 정보 위치에 민감하게 반응하여 시각 영역에서 '중간 손실' 현상이 나타납니다.
이에 대해 우리는 선도적인 Visual Retriever-Augmented Generator(visual-RAG) 프레임워크인 MIRAGE를 제안합니다. MIRAGE는 혁신적인 비주얼 토큰 압축기, 공동 훈련된 검색기, 증강된 다중 이미지 명령어 튜닝 데이터로 이러한 문제를 해결합니다.
이 블로그 포스팅을 살펴보신 뒤, 향후 모든 LMM 프로젝트에서 배포 전에 잠재적인 결함을 파악하고 수정하기 위해 Visual Haystacks 프레임워크를 사용해 모델을 벤치마킹해 보시기를 권장드립니다. 또한 커뮤니티가 진정한 범용 인공 지능(AGI)의 지평을 넓히기 위한 수단으로 다중 이미지 질문 답변을 살펴볼 것을 권장합니다.
참고자료: https://arxiv.org/abs/2407.13766
Visual Haystacks: Answering Harder Questions About Sets of Images
Recent advancements in Large Multimodal Models (LMMs) have made significant progress in the field of single-image visual question answering. However, these models face substantial challenges when tasked with queries that span extensive collections of image
arxiv.org
'BAIR' 카테고리의 다른 글
| [논문프리뷰] ChatGPT의 언어적 편향: 방언 차별을 강화하는 언어 모델 (0) | 2024.10.11 |
|---|---|
| LLM 모델의 탈옥 방법을 평가하는 방법: StrongREJECT 벤치마크를 사용한 연구사례 (0) | 2024.09.29 |
| TinyAgent: Edge에서의 함수 호출 (0) | 2024.06.30 |
| xT로 초대형 이미지 모델링하기(Modeling Extremely Large Images with xT) (0) | 2024.04.14 |
| AI 모델에서 복합 AI 시스템으로의 변화 (The Shift from Models to Compound AI Systems) (0) | 2024.03.23 |



