
늦깎이 공대생의 인공지능 연구실
FIGS: CART의 해석력과 속도로 XGBoost 수준의 성능 달성(Attaining XGBoost-level performance with the interpretability and speed of CART) 본문
FIGS: CART의 해석력과 속도로 XGBoost 수준의 성능 달성(Attaining XGBoost-level performance with the interpretability and speed of CART)
Justin T. 2022. 11. 2. 00:16

최근 기계학습의 발전은 종종 해석력을 희생하면서 점점 더 복잡한 예측 모델로 발전하였습니다. 우리는 종종 해석력이 필요하며, 특히 임상 의사 결정과 같은 고위험 적용에서 해석 가능한 모델은 오류 식별, 도메인 지식 활용 및 신속한 예측과 같은 모든 종류의 해석을 도와줍니다.
이번 포스팅에서는 트리 합계의 형태를 취하는 해석할 수 있는 모델을 적합화하는 새로운 방법인 FIGS에 대해 다루고자 합니다. 실제 실험과 이론적 결과에 따르면 FIGS는 데이터의 광범위한 구조에 효과적으로 적응하여 해석력을 희생하지 않고 여러 설정에서 최첨단 성능을 달성할 수 있습니다.
FIGS의 동작 원리
직관적으로, FIGS는 의사결정 트리를 성장시키기 위한 전형적인 탐욕 알고리즘인 CART를 확장하여 트리 합계를 동시에 성장시키는 것을 고려합니다(위 그림 참조). 각 반복에서, FIGS는 이미 시작한 기존 트리를 성장시키거나 새 트리를 시작할 수 있습니다. 설명되지 않은 총 분산(또는 대체 분할 기준)을 가장 많이 줄이는 규칙을 탐욕스럽게 선택합니다. 트리가 서로 동기화되도록 각 트리는 다른 모든 트리의 예측을 합친 후 남은 잔차(Residual)를 예측합니다.
FIGS는 기울기 부스팅/랜덤 포레스트와 같은 앙상블 접근법과 직관적으로 유사하지만, 중요한 것은 모든 트리가 서로 경쟁하도록 성장하기 때문에 모델이 데이터의 기본 구조에 더 잘 적응할 수 있다는 것입니다. 트리 수와 각 트리의 크기/모양은 수동으로 지정하지 않고 데이터에서 자동으로 나타납니다.
FIGS는 개별 트리뿐만 아니라 트리의 앙상블 내에서 분할을 고려하여 한 번에 하나씩 노드를 추가합니다. 이렇게 하면 반복적인 분할을 피할 수 있기 때문에 훨씬 더 컴팩트한 모델을 만들 수 있습니다.
FIGS를 사용한 예제
FIGS 사용하는 것은 매우 간단합니다. imodels 패키지(pip install imodels)를 통해 쉽게 설치할 수 있으며 표준 sickit-learn 모델과 동일한 방식으로 사용할 수 있습니다. 분류기 또는 회귀기를 가져오고 적합(fit) 및 예측(predict) 방법을 사용합니다. 다음은 대상이 경추 손상 위험(CSI)인 샘플 임상 데이터셋에 사용하는 예제입니다.
from imodels import FIGSClassifier, get_clean_dataset
from sklearn.model_selection import train_test_split
# prepare data (in this a sample clinical dataset)
X, y, feat_names = get_clean_dataset('csi_pecarn_pred')
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
# fit the model
model = FIGSClassifier(max_rules=4) # initialize a model
model.fit(X_train, y_train) # fit model
preds = model.predict(X_test) # discrete predictions: shape is (n_test, 1)
preds_proba = model.predict_proba(X_test) # predicted probabilities: shape is (n_test, n_classes)
# visualize the model
model.plot(feature_names=feat_names, filename='out.svg', dpi=300)위 코드를 통해 간단한 모델이 생성됩니다. 즉, 4개의 분할만 포함됩니다(왜냐하면 모델에 4개 이하의 분할이 있어야 한다고 다음과 같이 지정했기 때문입니다(max_rules=4)). 예측은 모든 트리에서 표본을 추출하고 각 트리의 결과 노드에서 얻은 위험조정값(risk adjustment values)을 합하여 이루어집니다. 이 모델은 의사선생님이 이제 (i) 4가지 관련 특성을 사용하여 쉽게 예측할 수 있고 (ii) 모델을 검토하여 도메인 전문 지식과 일치하는지 확인할 수 있기 때문에 해석력이 매우 높아집니다. 이 모델은 단지 설명을 위한 것이며 ~84\%의 정확도를 달성합니다.
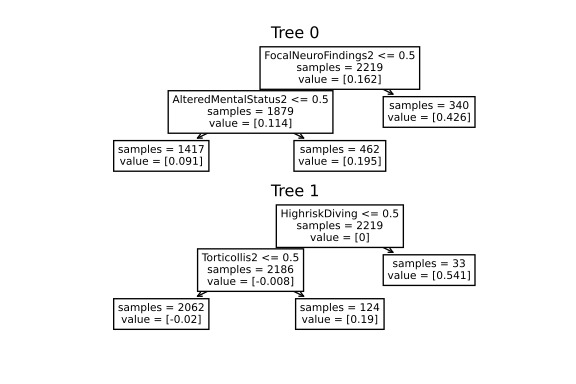
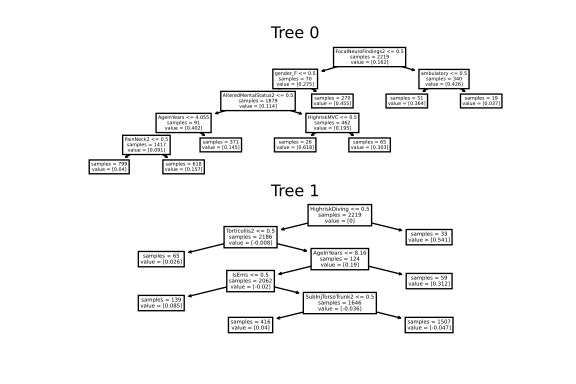
좀 더 유연한 모델을 원한다면 규칙 수에 대한 제약도 제거할 수 있습니다. model = FIGSClassifier()로 코드를 변경하여 모델을 더 크게 만들 수 있습니다(아래 그림 참조). 트리 수와 트리 균형 조정 방법은 데이터 구조에서 나타나며, 총 규칙 수만 지정할 수 있습니다.
FIGS는 어떻게 성능을 개선했을까?
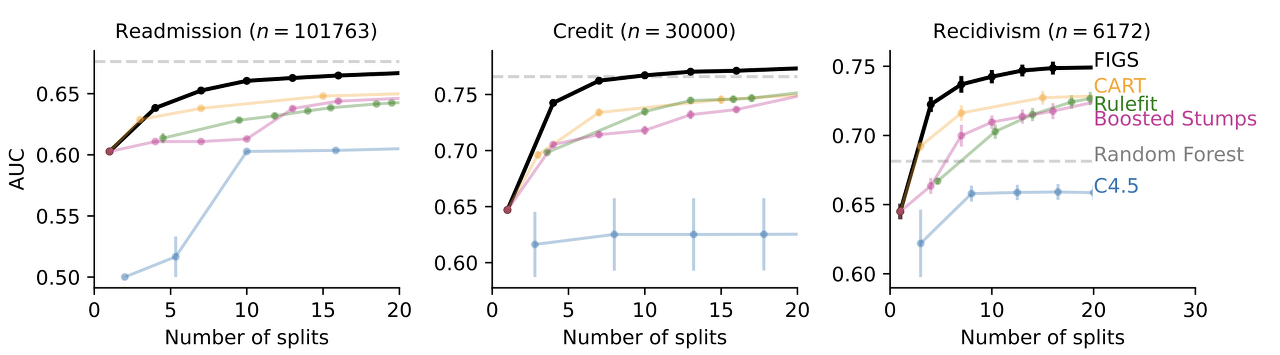
임상 의사결정 규칙 모델링과 같이 해석력이 필요한 많은 경우에서, FIGS는 최첨단 성능을 달성할 수 있습니다. 예를 들어, 다음 그림은 FIGS가 우수한 성능을 달성하는 다양한 데이터셋을 보여줍니다. 특히 전체 분할을 거의 사용하지 않는 경우에 더욱 뚜렷이 나타나는 것을 보실 수 있습니다.
왜 FIGS의 성능이 좋은것일까?
단일 결정 트리가 데이터에 추가적인 구조가 있을 때, 발생할 수 있는 서로 다른 가지에서 반복되는 분할을 갖는 경우가 많다는 관찰 결과는 FIGS를 사용하게 되는 동기 부여가 됩니다. 여러 개의 트리가 있으면 추가 구성요소를 별도의 트리로 분리하여 이러한 문제를 방지할 수 있습니다.
결론
전반적으로 해석할 수 있는 모델링은 일반적인 블랙박스 모델링에 대한 대안을 제공하며, 많은 경우 성능 손실 없이 효율성과 투명성 측면에서 엄청난 개선을 제공할 수 있습니다.
참고자료: https://bair.berkeley.edu/blog/2022/06/30/figs/
FIGS: Attaining XGBoost-level performance with the interpretability and speed of CART
The BAIR Blog
bair.berkeley.edu



