
늦깎이 공대생의 인공지능 연구실
[용어정리]Weight Decay 본문
요즘 AI모델 성능 고도화를 위이 어떻게 하면 좋을지 Fine-Tuning을 하기 위해 학습 설정값들을 조금씩 바꾸면서 AI모델의 성능을 향상시키는데 열중하고 있습니다. 그러던 와중 Weight Decay값인 λ를 조절해보고 있는데, 이 값을 조정하였을 때 AI모델의 Weight에 어떻게 영향을 주는지 궁금해졌습니다. 제가 딥러닝을 공부하던 당시에는 Weight Decay를 설정하여 Overfitting을 막는다는 정도로만 배우고 이해하고 있었는데 실무에서 Weight Decay를 마주하게 되니 막상 이론으로 배웠던 용어가 실제 내가 다루고 있는 AI모델 성능 향상을 위해 어떻게 적용해야 하는지 잠시 궁금했습니다.
먼저, Weight Decay가 모델 성능을 향상시킬 수 있는 이유에 대해 Chat GPT에게 물어보았습니다.
Weight Decay는 머신 러닝 모델의 일반화 성능을 향상시키기 위해 사용되는 정규화 기법 중 하나입니다. Weight Decay를 사용하여 Weight의 크기를 최소화하는 것이 좋은 이유는 다음과 같습니다.
1. 과적합 방지
큰 weight값은 모델이 학습 데이터에 과적합(Overfitting)될 가능성을 높입니다. 과적합된 모델은 학습 데이터에는 잘 맞지만, 새로운 데이터에 대해서는 성능이 떨어집니다. Weight Decay는 Weight값을 작게 유지함으로써 모델이 학습 데이터의 노이즈에 덜 민감하게 만들어 과적합을 방지합니다.
2. 모델 단순화
작은 Weight값은 모델을 더 단순하게 만듭니다. 단순한 모델은 해석하기 쉽고, 일반적으로 더 좋은 일반화 성능을 보입니다. 이는 모델이 불필요하게 복잡해지는 것을 막아주고, 중요한 특징만을 학습하도록 도와줍니다.
3. 수치적 안정화
큰 Weight 값은 수치적 불안정을 초래할 수 있습니다. 예를 들어, 큰 Weight값은 활성화 함수의 출력이 매우 큰 값이나 매우 작은 값으로 포화(Saturation)된 가능성을 높입니다. 이는 역전파 과정에서 기울기 소실(Vanishing gradient)이나 기울기 폭발(Exploding gradient) 문제를 일으킬 수 있습니다. Weight decay는 이러한 문제를 완화시켜줍니다.
4. 일반화 성능 향상
Weight Decay는 모델의 학습 데이터에 대한 일반적인 패턴을 더 잘 학습하도록 도와줍니다. 이는 모델이 새로운 데이터에 대해 더 나은 예측 성능을 보이게 합니다.
Weight Decay는 일반적으로 L2 정규화로 구현되며, 손실 함수에 Weight의 제곱합을 추가하여 Weight값이 커지는 것을 억제합니다. 이를 통해 모델의 복잡성을 제어하고, 더 나은 일반화 성능을 얻을 수 있습니다.
ChatGPT의 설명에 따르면, AI모델이 Train 데이터셋을 학습하는 과정에서 Weight decay를 도입하여 AI모델의 크기를 줄임으로서 과적합(Overfitting)을 방지할 수 있다는 것으로 이해됩니다. 이는 AI모델의 Regularization 단게에서 L2 정규화로 적용되고 있으며, L2 정규화 식은 다음과 같습니다.

위 식을 보았을 때 학습 과정에서 적용되는 loss값은 AI모델의 추론값과 실제값의 차이인 \(|\hat{y}-y|\)에 L2 정규화인 \(\lambda W^TW\)을 더한 값임을 확인할 수 있습니다. 이 때 \(\lambda W^TW\)는 Weight값 자신을 제곱한 값으로 Weight값 자신을 나타낸다고 볼 수 있습니다.
위 식을 보면서 저는 Weight decay의 효과에 대해 강한 의문이 생기게 되었습니다.
모델의 크기가 커지지 않게 하는 것이 과적합을 막는 것과 무슨 상관이 있는거지?
혹시 당신이 이러한 의문을 가지고 계셨다면 지금부터 제가 설명드리는 내용을 통해 이 의문을 확실히 해결하실 수 있으실겁니다.
먼저, 다음과 같이 AI모델과 Train 데이터셋이 있다고 칩시다.

AI모델은 해당 Train 데이터셋을 학습하면서 최적의 성능을 도출하려 할 것입니다. 학습 횟수가 많아질 수록 AI모델은 Train 데이터셋에 점점 fitting이 되면서 우리가 원하는 결과에 도달할 것이라 생각할 수 잇지요.

그러나, 과도한 학습이 이루어지게 될 경우 AI모델은 Train 데이터셋에 완전 적합한 Weight값들을 가지게 되나 학습되지 않은 데이터가 입력될 경우 원하는 성능이 나오지 않을 가능성이 큽니다. 위의 그림에서 보면 아시듯이, Overfitting된 AI모델의 Weight값은 Train 데이터셋에 완전히 최적화 되어 비중이 커져버린 것을 확인하실 수 있습니다.
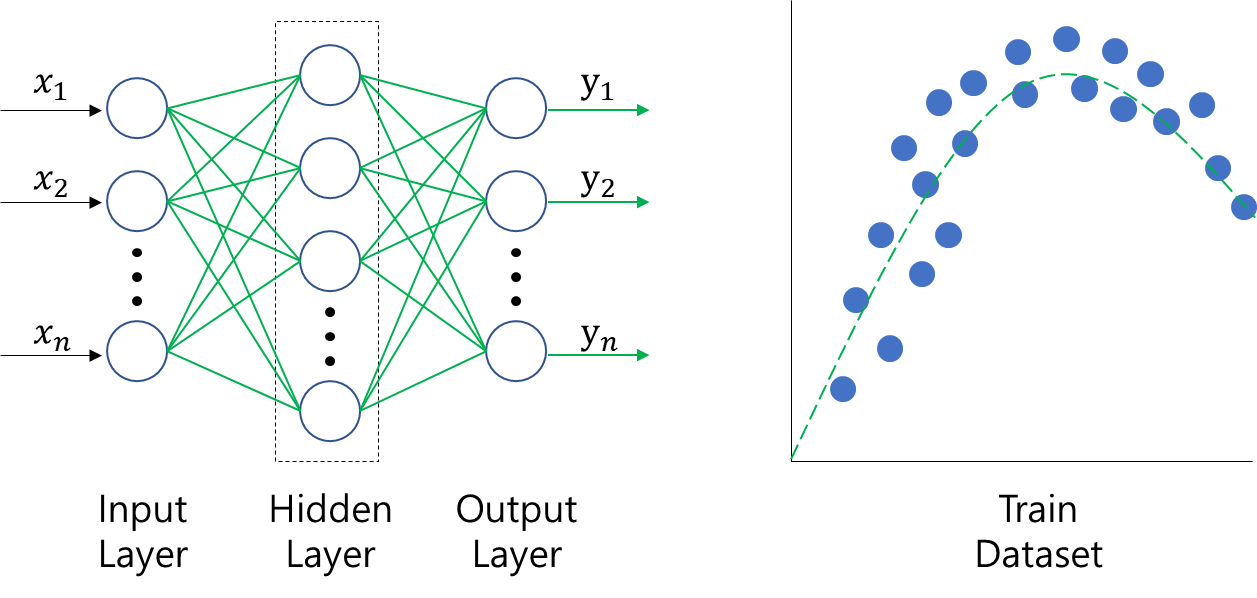
Weight Decay가 적용된 L2정규화를 Loss에 포함하게 되면 AI모델이 Train 데이터셋을 학습하는 과정에서 예측값과 추론값의 차이 뿐 아니라 AI모델의 전체 Weight크기를 최소로 줄이는 방향으로 AI모델이 학습됨으로서, AI모델의 Weight값이 작아지게 되어 복잡도가 낮아져 Overfitting을 피함으로서 최적화된 AI모델을 만들어낼 수 있습니다.
Weight Decay를 설정할 때 적정한 λ을 설정하는 것이 중요합니다. 만약 λ를 0에 가깝게 설정하게 되면, Weight Decay를 설정하지 않았을 때와 비슷하게 AI모델이 Overfitting됩니다. 반면, λ를 너무 큰 값으로 설정하게 되면 AI모델의 Weight가 0에 가깝게 되어 학습이 전혀 되지 않을 가능성이 있습니다. 그러므로 AI모델 Fine Tuning과정에서 적정한 λ을 찾아낸다면 최적의 AI모델을 개발하실 수 있습니다.
'AI용어정리' 카테고리의 다른 글
| [용어정리]Synchronized Batch Normalization (0) | 2024.02.12 |
|---|---|
| [용어정리]Temporal difference learning(시간차 학습) (0) | 2022.12.10 |
| [용어정리]Ground-truth (9) | 2020.02.25 |
| [용어 정리] Hypothesis set(가설집합) (0) | 2019.10.30 |



