

늦깎이 공대생의 인공지능 연구실
[논문프리뷰]교통 원활화를 위한 강화 학습 확장: 100대의 자율주행 차랑으로 고속도로에 적용한 사례(Scaling Up Reinforcement Learning for Traffic Smoothing: A 100-AV Highway Deployment) 본문
[논문프리뷰]교통 원활화를 위한 강화 학습 확장: 100대의 자율주행 차랑으로 고속도로에 적용한 사례(Scaling Up Reinforcement Learning for Traffic Smoothing: A 100-AV Highway Deployment)
Justin T. 2025. 3. 31. 00:33
강화학습(RL)으로 제어되는 차량 100대를 출퇴근 시간대 고속도로 교통 체증에 투입하여 교통 체증을 완화하고 모든 차량의 연료 소비를 줄이는 데 성공했습니다. 우리의 목표는 일반적으로 명확한 원인은 없지만 정체를 유발하고 상당한 에너지 낭비를 초래하는 ''스톱 앤 고'' 현상을 해결하는 것입니다. 효율적인 흐름 원활화 제어 솔루션을 훈련하기 위해 우리는 RL 에이전트가 상호 작용하는 빠른 데이터 기반 시뮬레이션을 구축하여 처리량을 유지하면서 에너지 효율을 극대화하고 인간 운전자가 안전하게 운행할 수 있는 방법을 학습했습니다.
전반적으로, 잘 제어된 자율주행차(AV)의 소수는 도로의 모든 운전자의 교통 흐름과 연비를 크게 개선하기에 충분합니다. 또한, 훈련된 차량 제어 시스템은 대부분의 최신 차량에 배치할 수 있도록 설계되어 분산된 방식으로 작동하며 표준 레이더 센서에 의존합니다. 이번 블로그에서는 100대의 차량을 대상으로 한 실험을 통해 시뮬레이션부터 현장까지 대규모로 RL 컨트롤러를 배포할 때의 기술적 도전에 대해 살펴봅니다.
유령 정체(Phantom jams)에 대한 도전

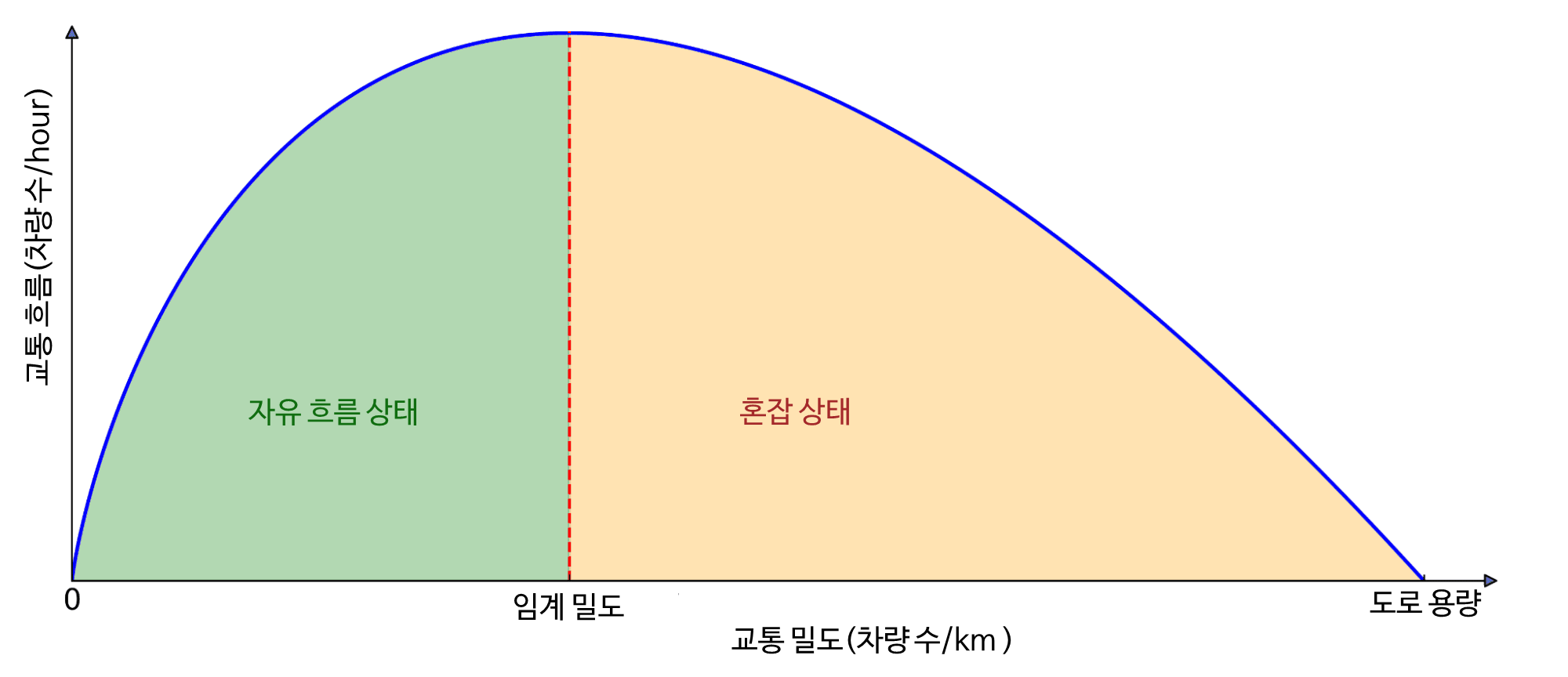
운전을 하다 보면 갑자기 나타났다가 갑자기 풀리는 정체 현상인 스톱 앤 고 현상을 경험한 적이 있을 것입니다. 이러한 정체 현상은 교통 흐름에 따라 증폭되는 운전 습관의 작은 변동으로 인해 발생하는 경우가 많습니다. 우리는 자연스럽게 앞 차량에 따라 속도를 조절합니다. 앞차와의 간격이 벌어지면 따라잡기 위해 속도를 높입니다. 상대방이 브레이크를 밟으면 우리도 속도를 줄입니다. 하지만 사람의 반응 시간은 0이 아니기 때문에 앞 차량보다 조금 더 세게 브레이크를 밟을 수 있습니다. 뒤따라오는 운전자도 같은 행동을 하고, 이런 상황이 계속 반복됩니다. 시간이 지남에 따라 미미한 감속으로 시작했던 것이 교통 체증으로 인해 완전히 멈추는 상황으로 바뀝니다. 이러한 영향으로 교통 흐름이 후방으로 이동하면서 잦은 가속으로 인해 에너지 효율이 크게 떨어지고 CO2 배출량과 사고 위험이 증가합니다.
그리고 이는 고립된 현상이 아닙니다! 교통 밀도가 임계치를 초과하는 혼잡한 도로에서 이러한 현상은 어디서나 볼 수 있습니다. 그렇다면 이 문제를 어떻게 해결할 수 있을까요? 램프 계량 및 가변 속도 제한과 같은 전통적인 접근 방식으로 교통 흐름을 관리하려고 시도하지만, 이는 비용이 많이 드는 인프라 및 중앙 집중식 작업이 필요한 경우가 많습니다. 보다 확장 가능한 접근 방식은 실시간으로 운전 행동을 동적으로 조정할 수 있는 자율주행차(AV)를 사용하는 것입니다. 그러나 단순히 인간 운전자 사이에 AV를 투입하는 것만으로는 충분하지 않으며, 모든 사람에게 더 나은 교통 환경을 조성하는 더 스마트한 방식으로 운전해야 하는데, 바로 이 부분에서 RL이 필요합니다.
AV의 움직임 원활화를 위한 강화 학습
RL은 에이전트가 환경과의 상호작용을 통해 보상 신호를 극대화하는 방법을 학습하는 강력한 제어 방식입니다. 에이전트는 시행착오를 통해 경험을 수집하고 실수를 통해 학습하며 시간이 지남에 따라 개선됩니다. 이 경우 환경은 혼합 자율 주행 교통 시나리오로, 자율 주행 차량이 스톱앤고 현상을 완화하고 자신과 주변의 인간 운전 차량 모두의 연료 소비를 줄이기 위한 주행 전략을 학습합니다.
이러한 RL 에이전트를 훈련하려면 고속도로의 스톱 앤 고 동작을 재현할 수 있는 사실적인 교통 역학으로 빠른 시뮬레이션이 필요합니다. 이를 위해 미국 테네시주 내슈빌 인근의 24번 고속도로(I-24)에서 수집한 실험 데이터를 활용하여 차량이 고속도로 경로를 재연하는 시뮬레이션을 구축함으로써 뒤에서 주행하는 자율주행차가 불안정한 교통 상황을 학습하는 데 활용했습니다.
여러 차례 가다 서다를 반복하는 고속도로 궤적을 재생하는 시뮬레이션.
우리는 자율주행차가 자신과 앞 차량에 대한 기본적인 센서 정보만으로 작동할 수 있도록 배치를 염두에 두고 설계했습니다. 관측 정보는 자율주행차의 속도, 선행 차량의 속도, 차량 간 간격으로 구성됩니다. 이러한 입력이 주어지면 RL 에이전트는 AV의 순간 가속 또는 원하는 속도를 지정합니다. 이러한 로컬 측정값만 사용할 때의 주요 장점은 추가 인프라 없이도 대부분의 최신 차량에 분산된 방식으로 RL 컨트롤러를 적용할 수 있다는 점입니다.
보상 설계
가장 어려운 부분은 보상 함수를 최대화했을 때 AV가 달성하고자 하는 다양한 목표에 부합하는 보상 함수를 설계하는 것입니다.
- 파동 완만화: 스톱 앤 고 동작 진동을 줄입니다..
- 에너지 효율: 자율주행차뿐만 아니라 모든 차량의 연료 소비를 줄입니다.
- 안전: 적절한 차간 거리를 확보하고 급제동을 피합니다.
- 편안한 주행: 급가속과 급감속을 피합니다.
- 인간의 운전 규범 준수: 주변 운전자를 불편하게 하지 않는 '정상적인' 운전 행동을 유지합니다.
각 조건에 적합한 계수를 찾아야 하므로 이러한 목표들 간의 균형을 맞추는 것은 어렵습니다. 예를 들어, 연료 소비를 최소화하는 것이 보상을 지배하는 경우, RL 자율주행차는 고속도로 중간에서 정차하는 것이 에너지를 최적화하는 방법이라고 학습하게 됩니다. 이를 방지하기 위해 동적 최소 및 최대 간격 임계값을 도입하여 안전하고 합리적인 행동을 보장하는 동시에 연료 효율을 최적화하도록 했습니다. 또한 자율주행차 뒤에서 사람이 운전하는 차량의 연료 소비에 불이익을 주어 주변 교통량을 희생하면서까지 자율주행차의 에너지 절약을 최적화하는 이기적인 행동을 학습하지 못하도록 했습니다. 전반적으로 에너지 절약과 합리적이고 안전한 운전 행동 사이의 균형을 맞추는 것을 목표로 합니다.
시뮬레이션 결과
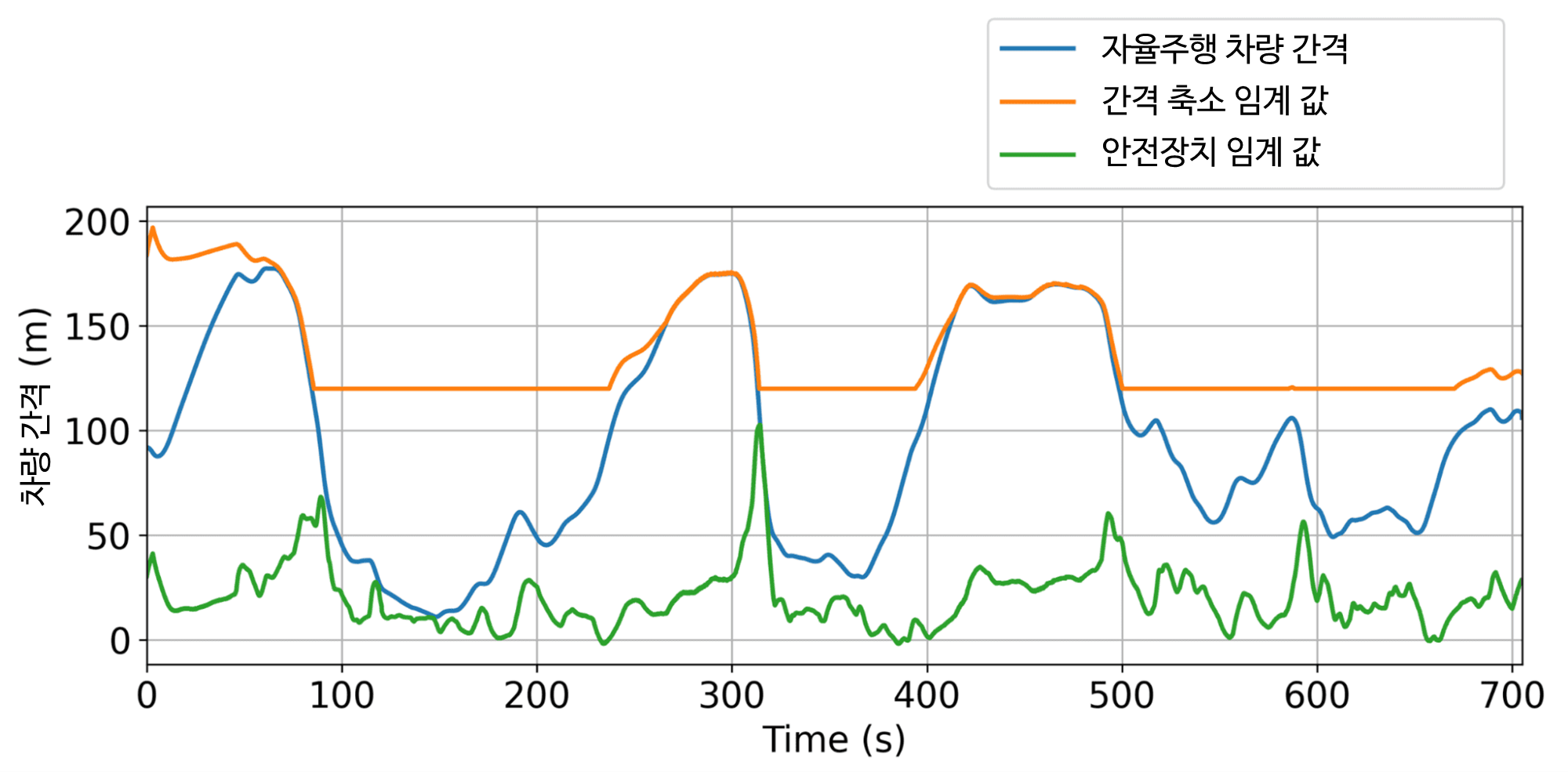
자율주행차가 학습한 일반적인 행동은 인간 운전자보다 약간 더 큰 간격을 유지하여 다가오는 갑작스러운 교통 정체를 더 효과적으로 흡수할 수 있도록 하는 것입니다. 시뮬레이션 결과, 이 접근 방식은 가장 혼잡한 시나리오에서 모든 도로 사용자에 걸쳐 최대 20%의 상당한 연료 절감 효과를 가져왔으며, 도로에 있는 AV의 비율은 5% 미만이었습니다. 그리고 이러한 자율주행차는 특수 차량일 필요는 없습니다! 스마트 어댑티브 크루즈 컨트롤(ACC)이 장착된 일반 소비자용 자동차도 대규모로 테스트할 수 있습니다.

100 AV 현장 테스트: 대규모 RL 적용하기

시뮬레이션 결과가 예상대로 좋았기 때문에 자연스럽게 다음 단계는 시뮬레이션을 고속도로에 적용하는 것이었습니다. 우리는 훈련된 RL 제어 시스템을 며칠에 걸쳐 교통량이 가장 많은 시간대에 I-24 고속도로에 100대의 차량에 배치했습니다. 'MegaVanderTest'라고 이름 붙인 이 대규모 실험은 지금까지 수행된 혼합 자율 주행 교통 원활화 실험 중 가장 큰 규모입니다.
현장에 RL 제어 시스템을 배포하기 전에 시뮬레이션을 통해 광범위하게 훈련 및 평가를 하고 하드웨어에서 검증을 거쳤습니다. 전반적으로 배포를 위한 단계는 다음과 같습니다.
- 데이터 기반 시뮬레이션을 통한 학습: I-24의 고속도로 교통 데이터를 사용하여 사실적인 도로 교통 흐름을 갖춘 학습 환경을 만든 다음, 다양한 새로운 교통 시나리오에서 학습된 에이전트의 성능과 강건성을 검증했습니다.
- 하드웨어에 적용: 로보틱스 소프트웨어에서 검증을 거친 후 학습된 제어 시스템을 차량에 업로드하여 차량의 설정 속도를 제어할 수 있습니다. 차량에 탑재된 크루즈 컨트롤을 통해 작동하며, 이는 하위 수준의 안전 제어장치 역할을 합니다.
- 모듈식 제어 프레임워크: 테스트 중 주요 차량 정보 센서에 액세스할 수 없다는 점이 주요 난제 중 하나였습니다. 이를 극복하기 위해 RL 컨트롤러는 후방 교통 상황을 고려하는 속도 조절 가이드와 최종 의사 결정권자인 RL 컨트롤러를 결합한 계층적 시스템인 'MegaController'에 통합되었습니다.
- 하드웨어 검증: RL 에이전트는 대부분의 차량이 사람이 운전하는 환경에서 작동하도록 설계되었기 때문에 예측할 수 없는 행동에 적응하는 강력한 정책이 필요했습니다. 이를 검증하기 위해 사람의 세심한 지도 감독 하에 RL 제어 차량을 도로에서 주행하고 피드백에 따라 제어를 변경합니다.


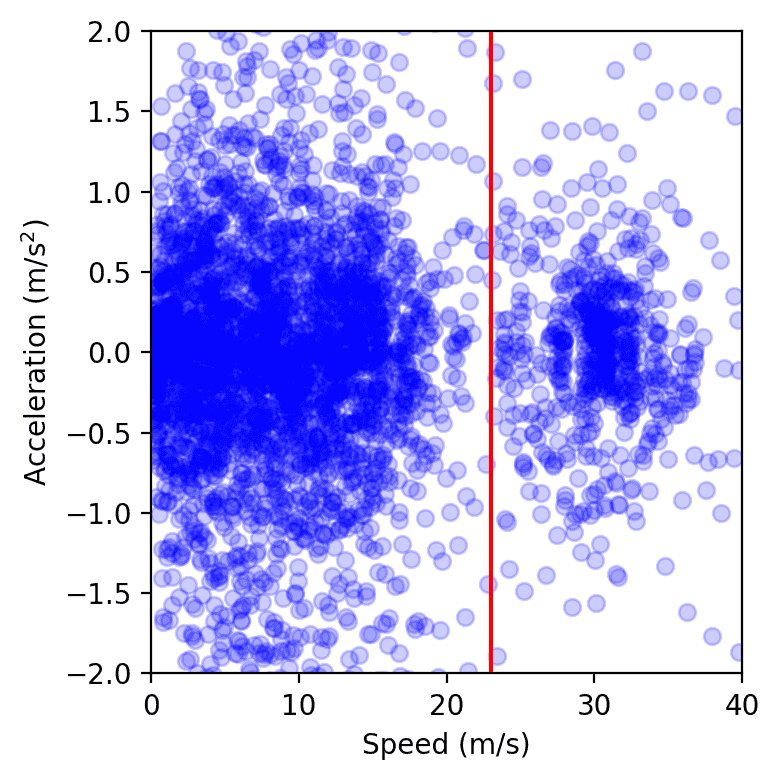
검증이 완료된 RL 컨트롤러는 100대의 차량에 배치되어 아침 출근 시간 동안 I-24 도로에서 주행되었습니다. 주변 차량은 실험을 인지하지 못하도록 하여 운전자들이 편견 없이 행동할 수 있도록 했습니다. 실험이 진행되는 동안 고속도로를 따라 설치된 수십 대의 카메라에서 데이터를 수집하여 컴퓨터 비전 파이프라인을 통해 수백만 개의 개별 차량 궤적을 추출했습니다. 이러한 경로에서 계산된 메트릭은 시뮬레이션 결과와 이전의 소규모 검증 배포에서 예상한 대로 자율주행차 주변의 연료 소비가 감소하는 추세를 보여줍니다. 예를 들어, 사람들이 자율주행차 뒤에 가까이 다가갈수록 평균적으로 연료 소비량이 줄어드는 것을 관찰할 수 있습니다(이는 보정된 에너지 모델을 사용하여 계산됨)

자동차의 영향을 측정하는 또 다른 방법은 속도와 가속도의 분산을 측정하는 것입니다. 분산이 낮을수록 자동차의 주행 진폭이 작아지는데, 이는 현장 테스트 데이터에서 관찰되는 현상입니다. 전반적으로 많은 양의 카메라 비디오 데이터에서 정확한 측정값을 얻는 것은 복잡하지만, 제어 차량 주변에서 15~20%의 에너지 절감 추세를 관찰할 수 있었습니다.
최종 평가
100대의 차량이 참여한 이번 현장 운행 테스트는 자율주행차 간의 명시적인 협력이나 통신 없이 분산적으로 진행되었으며, 현재의 자율 주행 기술을 반영하고 더 원활하고 에너지 효율적인 고속도로에 한 걸음 더 다가갈 수 있는 계기가 되었습니다. 하지만 아직 개선할 수 있는 가능성은 무궁무진합니다. 더 나은 인간 운전 모델을 통해 시뮬레이션을 더 빠르고 정확하게 확장하는 것은 시뮬레이션과 현실의 간극을 좁히는 데 매우 중요합니다. 첨단 센서나 중앙 집중식 설정을 통해 자율주행차에 추가 교통 데이터를 제공하면 제어 시스템의 성능을 더욱 향상시킬 수 있습니다. 예를 들어, 멀티 에이전트 RL은 협력 제어 전략을 개선하는 데 도움이 될 수 있지만, 5G 네트워크를 통해 AV 간의 명시적 통신을 활성화하면 안정성을 더욱 개선하고 스톱 앤 고 현상을 더욱 완화할 수 있는지는 아직 미지수입니다. 결정적으로, 우리의 제어 시스템은 기존의 어댑티브 크루즈 컨트롤(ACC) 시스템과 원활하게 통합되어 대규모 현장 적용이 가능합니다. 스마트 교통 흐름 원활화 제어 시스템이 장착된 차량이 많아질수록 도로에서 볼 수 있는 교통 체증은 줄어들고, 이는 곧 공해와 연료 절감으로 이어질 것입니다!
참고자료: https://ieeexplore.ieee.org/document/10858625
Reinforcement Learning-Based Oscillation Dampening: Scaling Up Single-Agent Reinforcement Learning Algorithms to a 100-Autonomou
In this article, we explore the technical details of the reinforcement learning (RL) algorithms that were deployed in the largest field test of automated vehicles designed to smooth traffic flow in history as of 2023, uncovering the challenges and breakthr
ieeexplore.ieee.org



