
늦깎이 공대생의 인공지능 연구실
[논문 프리뷰] 강화학습으로 확산 모델 훈련하기(Training Diffusion Models with Reinforcement Learning) 본문
[논문 프리뷰] 강화학습으로 확산 모델 훈련하기(Training Diffusion Models with Reinforcement Learning)
Justin T. 2023. 8. 14. 19:44
최근 확산 모델(Diffusion Model)이 복잡하고 고차원적인 결과물을 생성하는 사실상 표준으로 부상했습니다. 확산 모델은 멋진 AI 아트와 초현실적인 합성 이미지를 생성하는 기능으로 잘 알려져 있지만, 약물 설계 및 연속 제어와 같은 다른 분야에서도 성공을 거두었습니다. 확산 모델의 핵심 아이디어는 무작위 노이즈를 이미지나 단백질 구조와 같은 샘플로 반복적으로 변환하는 것입니다. 이는 일반적으로 최대 가능성 추정 문제(Maximum Likelihood Estimation)로 동기가 부여되며, 모델은 훈련 데이터와 최대한 가깝게 일치하는 샘플을 생성하도록 훈련됩니다.
그러나 확산 모델의 대부분의 사용 사례들은 훈련 데이터의 매칭에 직접적으로 관여하는 것이 아니라 다운스트림 목표와 관련이 있습니다. 단순히 기존에 있던 이미지처럼 보이는 것이 아닌, 특정 유형의 이미지를 원하였으며, 물리적으로 그럴듯한 약물 분자가 아닌, 가능한 한 효과적인 약물 분자를 원합니다. 이 포스팅에서는 강화 학습(Reinforcement Learning)을 사용하여 이러한 다운스트림 목표에 대해 확산 모델을 직접 훈련할 수 있는 방법을 보여줍니다. 이를 위해 이미지 압축성, 사람이 인지하는 미적 품질, 즉각적인 이미지 정렬 등 다양한 목표에 대해 Stable Diffusion을 강화학습으로 미세 조정합니다. 마지막 목표는 대규모 비전 언어 모델의 피드백을 사용하여 비정상적인 프롬프트에서 모델의 성능을 개선하는 것으로, 사람이 개입하지 않고도 강력한 AI 모델을 사용하여 서로를 개선할 수 있음을 보여줍니다.
노이즈 제거 확산 정책 최적화(Denoising Diffusion Policy Optimization)
확산 모델을 RL 문제로 전환할 때 가장 기본적인 가정은 샘플(예: 이미지)이 주어지면 해당 샘플이 얼마나 '좋은' 샘플인지 평가할 수 있는 보상 함수에 접근할 수 있다는 것입니다. 우리의 목표는 확산 모델이 이 보상 함수를 최대화하는 샘플을 생성하는 것입니다.
확산 모델은 일반적으로 최대 가능성 추정(MLE)에서 파생된 손실 함수를 사용하여 훈련되는데, 이는 훈련 데이터가 더 가능성이 높아 보이는 샘플을 생성하도록 권장된다는 의미입니다. RL 설정에서는 더 이상 학습 데이터가 없고 확산 모델의 샘플과 관련 보상만 있습니다. 샘플을 훈련 데이터로 취급하고 각 샘플의 손실에 보상에 따라 가중치를 부여하여 보상을 통합함으로써 동일한 MLE 동기 손실 함수를 계속 사용할 수 있는 한 가지 방법이 있습니다. 이렇게 하면 RL의 기존 알고리즘을 따서 보상 가중 회귀(RWR)라고 부르는 알고리즘을 얻을 수 있습니다.
하지만 이 접근 방식에는 몇 가지 문제가 있습니다. 하나는 RWR이 특별히 정확한 알고리즘이 아니며 보상을 대략적으로만 최대화한다는 점입니다(Nair et. al., Appendix A). 확산에 대한 MLE에서 영감을 얻은 손실도 정확하지 않으며, 대신 각 샘플의 실제 가능성에 대한 변동 바운드(Variational Bound)를 사용하여 도출됩니다. 즉, RWR은 두 가지 수준의 근사치를 통해 보상을 최대화하지만, 이는 성능에 상당히 안좋은 영향을 주는 것으로 나타났습니다.

노이즈 제거 확산 정책 최적화(Denoising Diffusion Policy Optimization)라고 부르는 이 알고리즘의 핵심 내용은 노이즈 제거 단계의 전체 시퀀스에 집중하면 최종 샘플의 보상을 더 극대화할 수 있다는 것입니다. 이를 위해 확산 과정을 다단계 마르코프 결정 과정(Markov Decision Process)으로 재구성합니다. MDP 용어로 설명하자면, 각 노이즈 제거 단계는 하나의 작업이며, 에이전트는 최종 샘플이 생성될 때 각 노이즈 제거 궤적의 마지막 단계에 대해서만 보상을 받습니다. 이 프레임워크는 다단계 MDP를 위해 특별히 설계된 RL 라이브러리의 여러 강력한 알고리즘을 적용할 수 있게 해줍니다. 이러한 알고리즘은 최종 샘플의 대략적인 확률을 사용하는 대신 각 노이즈 제거 단계의 정확한 확률을 사용하므로 계산이 매우 쉽습니다.
구현이 쉽고 과거 언어 모델 Fine Tuning에서 성공했던 정책 그라데이션 알고리즘을 선택해 보았습니다. 그 결과 정책 그라데이션의 단순한 점수 함수 예측기인 REINFORCE로 알려진 \(DDPO_{SF}\)와 더 강력한 중요도 샘플링 예측기를 사용하는 \(DDPO_{IS}\) 두 가지 변형 DDPO를 도출하였습니다. \(DDPO_{IS}\)는 가장 성능이 좋은 알고리즘이며, 구현 방식은 근사 정책 최적화(Proximal Policy Optimization )와 거의 유사합니다.
DDPO를 사용한 Stable Diffusion 미세 조정(Finetuning Stable Diffusion Using DDPO)
주요 결과들은 \(DDPO_{IS}\)를 사용하여 Stable Diffusion v1-4를 미세 조정했습니다. 여기에는 각각 다른 보상 함수로 정의된 네 가지 작업이 있습니다:
- 압축성(Compressibility): JPEG 알고리즘을 사용하여 이미지를 얼마나 쉽게 압축할 수 있는가?
보상은 JPEG로 저장할 때 이미지의 음수 파일 크기(kB)입니다. - 비압축성(Incompressibility): JPEG 알고리즘을 사용하여 이미지를 압축하는 것이 얼마나 어려운가?
보상은 JPEG로 저장할 때 이미지의 양수 파일 크기(kB)입니다. - 미적 품질(Aesthetic Quality): 육안으로 보기에 이미지가 얼마나 미적으로 매력적인가?
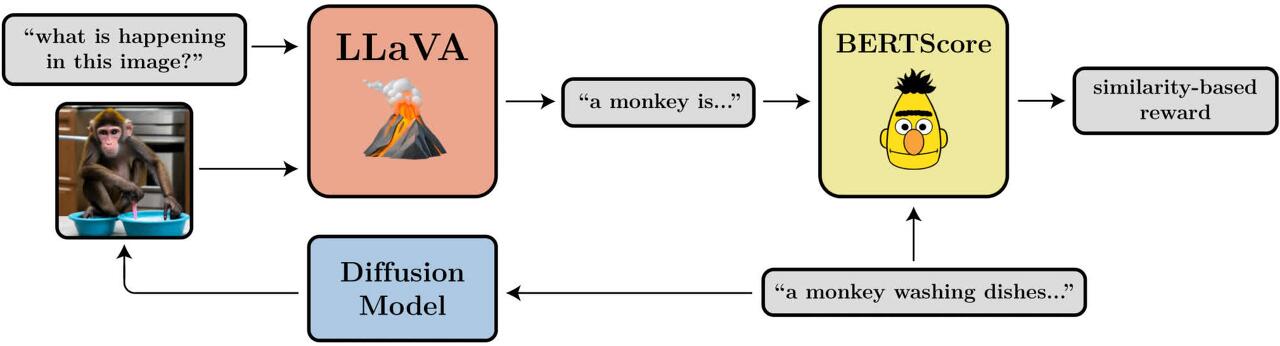
보상은 인간의 선호도에 대해 학습된 신경망인 LAION 미적 예측기의 출력입니다. - 프롬프트 이미지 정렬(Prompt-Image Alignment): 이미지가 프롬프트에서 요청한 내용을 얼마나 잘 표현하는가?
이 문제는 조금 더 복잡합니다. 이미지를 LLaVA에 입력하고, 이미지를 설명하도록 요청하고, 그 설명과 원래 프롬프트 간의 유사도를 BERTScore를 사용하여 계산합니다.
Stable Diffusion은 텍스트에서 이미지로 변환하는 모델이기 때문에 미세 조정 중에 제공할 프롬프트 셋도 선택해야 합니다. 처음 세 가지 작업에는 "a(n) [animal]" 형식의 간단한 프롬프트를 사용합니다. 프롬프트 이미지 정렬의 경우, '설거지 하기', '체스 게임하기', '자전거 타기'가 활동인 'a(n) [animal] [activity]' 형식의 프롬프트를 사용합니다. Stable Diffusion은 이러한 비정상적인 시나리오에서 프롬프트와 일치하는 이미지를 생성하는 데 어려움을 겪는 경우가 많았으며, RL 미세 조정을 통해 개선할 여지가 많다는 것을 발견했습니다.
먼저 간단한 보상(압축성, 비압축성, 미적 품질)에 대한 DDPO의 성능을 설명합니다. 모든 이미지는 동일한 무작위 시드로 생성되었습니다. 왼쪽 상단 사분면에서는 9가지 동물에 대해 "바닐라" Stable Diffusion이 생성하는 것을 보여 주며, 모든 RL 미세 조정 모델은 분명한 질적 차이를 보여줍니다. 흥미롭게도 미적 품질 모델(오른쪽 상단)은 최소한의 흑백 라인 그림을 선호하는 경향이 있으며, 이는 LAION 미적 예측기가 " '보다 미적'이라고 간주하는 " 이미지의 종류를 보여줍니다.

다음으로, 좀 더 복잡한 프롬프트와 이미지 정렬 작업에서 DDPO를 사용해 보겠습니다. 여기에서는 훈련 과정의 여러 스냅샷을 보여줍니다. 세 개의 이미지 시리즈 각각은 시간이 지남에 따라 동일한 프롬프트와 무작위 시드에 대한 샘플을 보여주며, 첫 번째 샘플은 바닐라 Stable Diffusion에서 생성된 것입니다. 흥미롭게도 모델이 좀 더 만화 같은 스타일로 바뀌는데, 이는 의도하지 않은 것입니다. 이는 사전 학습 데이터에서 인간과 유사한 활동을 하는 동물이 만화와 같은 스타일로 나타날 가능성이 높기 때문에 모델이 이미 알고 있는 것을 활용하여 프롬프트에 잘 맞추기 위해 이러한 스타일로 바뀐 것으로 추정됩니다.

의외의 일반화(Unexpected Generalization)
RL로 대규모 언어 모델을 미세 조정할 때 의외의 일반화가 발생하는 것으로 나타났습니다. 예를 들어, 영어로만 명령어 추종에 대해 미세 조정된 모델이 다른 언어에서도 개선되는 경우가 많다는 것이죠. 텍스트에서 이미지로의 확산 모델에서도 동일한 현상이 발생한다는 사실을 발견했습니다. 예를 들어, 미적 품질 모델은 45개의 일반적인 동물 목록에서 선택된 프롬프트를 사용하여 미세 조정되었습니다. 그 결과 보이지 않는 동물뿐만 아니라 일상적인 사물에도 일반화된다는 사실을 발견했습니다.

프롬프트 이미지 정렬 모델은 훈련 중에 동일한 45개의 일반적인 동물 목록과 단 3개의 Activity만 사용했습니다. 이 모델은 눈에 보이지 않는 동물뿐만 아니라 눈에 보이지 않는 활동, 심지어 이 두 가지의 새로운 조합까지 일반화한다는 사실을 발견했습니다.

과최적화(Overoptimization)
보상 함수, 특히 학습된 보상 함수를 미세 조정하면 모델이 보상 함수를 활용하여 불필요한 방식으로 높은 보상을 얻을 수 있는 보상 과최적화가 발생할 수 있다는 것은 잘 알려진 사실입니다. 이 설정도 예외는 아닙니다. 모든 작업에서 모델은 보상을 극대화하기 위해 결국 의미 있는 이미지 내용을 모두 파괴합니다.

또한 LLaVA가 타이포그래피 공격에 취약하다는 사실도 발견했습니다. "[n] animals" 형식의 프롬프트에 대한 정렬을 최적화할 때, DDPO는 정확한 숫자와 유사한 텍스트를 생성하여 LLaVA를 속이는 데 성공했습니다.

결론
확산 모델은 복잡하고 고차원적인 결과물을 생성하는 데 있어서는 타의 추종을 불허합니다. 하지만 지금까지는 이미지-캡션 쌍과 같이 수많은 데이터에서 패턴을 학습하는 것이 목표인 분야에서 주로 성공적이었습니다. 우리가 발견한 것은 패턴 매칭을 넘어서는 방식으로 확산 모델을 효과적으로 훈련할 수 있는 방법이며, 반드시 학습 데이터가 필요하지도 않습니다. 보상 함수의 품질과 창의성에 따라 가능성은 제한됩니다.
본 연구에서 DDPO를 사용한 방식은 최근 언어 모델 미세 조정에서 성공을 거둔 데서 영감을 받았습니다. Stable Diffusion과 같은 OpenAI의 GPT 모델은 먼저 방대한 양의 인터넷 데이터로 학습한 다음, RL을 통해 미세 조정하여 ChatGPT와 같은 유용한 도구를 생성합니다. 일반적으로 챗봇의 보상 함수는 사람의 선호도를 통해 학습되지만, 최근에는 AI 피드백에 기반한 보상 함수를 사용하여 강력한 챗봇을 생성하는 방법을 알아낸 곳도 있습니다. 챗봇 체제에 비해 우리의 실험은 규모가 작고 범위가 제한적입니다. 하지만 언어 모델링에서 '사전 학습 + 미세 조정' 패러다임이 거둔 엄청난 성공을 고려할 때, 확산 모델의 세계에서도 충분히 시도해 볼 만한 가치가 있는 것으로 보입니다. 다른 사람들이 우리의 연구를 바탕으로 텍스트-이미지 생성뿐만 아니라 비디오 생성, 음악 생성, 이미지 편집, 단백질 합성, 로보틱스 등과 같은 많은 흥미로운 애플리케이션에서 대규모 확산 모델을 개선할 수 있기를 바라고 있습니다.
하지만 "사전 학습 + 미세 조정" 패러다임이 DDPO를 사용하는 단 하나의 방법은 아닙니다. 보상 함수만 잘 갖춰져 있다면 처음부터 RL로 훈련하는 것을 멈출 필요는 없습니다. 이 설정은 아직 개척되지 않은 분야이지만, DDPO의 강점이 빛을 발할 수 있는 곳입니다. 순수한 RL은 게임부터 로봇 조작, 핵융합, 칩 설계에 이르기까지 다양한 영역에 오랫동안 적용되어 왔습니다. 여기에 확산 모델의 강력한 표현 능력을 더하면 기존 RL 응용 분야를 한 단계 발전시키거나 새로운 응용 분야를 발견할 수 있는 잠재력이 충분히 있습니다.
참고자료: https://rl-diffusion.github.io/
Training Diffusion Models with Reinforcement Learning
Training Diffusion Models with Reinforcement Learning UPDATE: We now have a PyTorch implementation that supports LoRA for low-memory training here! Summary We train diffusion models directly on downstream objectives using reinforcement learning (RL). We do
rl-diffusion.github.io



