
늦깎이 공대생의 인공지능 연구실
[논문프리뷰] RLHF(Reinforcement Learning with Human Feedback)에서 PPO(Proximal Policy Optimization)의 역할을 다시 생각하다 본문
[논문프리뷰] RLHF(Reinforcement Learning with Human Feedback)에서 PPO(Proximal Policy Optimization)의 역할을 다시 생각하다
Justin T. 2023. 10. 31. 01:31요약: RLHF에서는 사람의 선호도를 비교 형태로 사용하는 보상 학습 과정과, 비교를 하지 않는 단일 보상을 최적화하는 RL 미세 조정 과정 사이에 균형이 존재합니다. RL을 비교 방식으로 수행한다면 어떨까요?

대규모 언어 모델(LLM)은 GPT-4, Claude-2, Bard 및 Bing Chat과 같이 점점 더 뛰어난 기능을 갖춘 가상 도우미를 가능하게 하였습니다. 이러한 시스템은 복잡한 사용자 쿼리에 응답하고, 코드를 작성하고, 심지어 시를 창작할 수도 있습니다. 이러한 놀라운 가상 도우미의 근간이 되는 기술은 인간 피드백을 통한 강화학습(Reinforcement Learning with Human Feedback)입니다. RLHF는 모델을 사람이 설정한 의미 있는 값에 맞추어 사전 학습 단계에서 모델이 대량의 저품질 데이터에 노출되어 종종 발생할 수 있는 의도하지 않은 오류를 제거하는 것을 목표로 합니다.
이 과정에서 가장 많이 사용되는 RL 최적화 도구인 근거리 정책 최적화(Proximal Policy Optimization)는 불안정성과 구현상의 복잡성이 있는 것으로 보고되었습니다. 더 중요한 문제는 RLHF 프로세스에서는 보상 모델이 다양한 응답 간의 비교를 통해 학습되지만, RL 미세 조정 단계에서는 비교 없이 개별 응답에 대해 처리된다는 지속적인 불일치가 존재한다는 점입니다. 이러한 불일치는 특히 까다로운 언어 생성 영역에서 문제를 악화시킬 수 있습니다.
이러한 배경을 고려할 때 흥미로운 질문이 생겨납니다: 과연 비교 방식으로 학습하는 RL 알고리즘을 설계할 수 있을까요? 이를 탐구하기 위해 RLHF의 보상 학습 단계와 RL 미세 조정 단계의 학습 프로세스를 조화롭게 조정하여 이 문제에 대한 만족스러운 해결책을 제공하는 쌍방향 근사 정책 최적화(Pairwise Proximal Policy Opyimization, P3O)를 소개합니다.
배경
기존의 RL 환경에서 보상은 개발자가 수작업으로 지정하거나 아타리 게임처럼 잘 정의된 보상 함수에 의해 제공됩니다. 그러나 모델이 유용하고 안전한 반응을 유도하려면 좋은 보상을 정의하는 것이 간단하지 않습니다. RLHF는 사람의 피드백, 특히 비교를 통해 보상 함수를 학습한 다음 RL을 적용하여 학습된 보상 함수를 최적화함으로써 이 문제를 해결합니다.
RLHF 파이프라인은 다음과 같이 여러 단계로 나뉩니다.
지도 미세 조정 단계(Supervised Fine-Tuning Stage): 사전 학습된 모델은 고품질 데이터셋에서 최대한의 가능성 손실을 거치며 모방을 통해 사람의 쿼리에 응답하는 방법을 학습합니다.
보상 모델링 단계(Reward Modeling Stage): SFT 모델에서
RL 미세 조정 단계(RL Fine-Tuning Stage): SFT 모델은 본 단계의 초기화 역할을 하며, RL 알고리즘은 초기 정책과의 편차를 제한하면서 보상을 극대화하는 방향으로 정책을 최적화합니다. 공식적으로 이 단계에서는 다음과 같이 수행됩니다.
이 접근법의 본질적인 문제는 보상의 비독점성입니다. 예를 들어, 보상함수
P3O 유도
우리의 아이디어는 VPG(Vanilla Policy Gradient)에서 비롯되었습니다. VPG는 널리 채택된 1차 RL 최적화 기법으로, 단순하고 구현하기 쉽다는 점에서 선호되고 있습니다. CB(Contextual Bandit) 설정에서 VPG는 다음과 같이 표현됩니다.
몇 가지 대수적 조정을 통해 동일한 프롬프트에 대한 두 가지 응답을 포함하는 비교 형식의로 정책 경사도(Policy Gradient)를 다시 작성할 수 있습니다. 이를 쌍방향 정책 경사도(Pairwise Policy Gradeint)라고 합니다.
보상의 절대적인 규모에 직접적으로 의존하는 VPG와 달리, PPG는 보상 간의 격차를 이용합니다. 이를 통해 앞서 언급한 보상 변환 문제를 우회할 수 있습니다. 성능을 더욱 향상시키기 위해 Importance Sampling을 사용하여 리플레이 버퍼를 통합하고 Clipping을 통한 대규모 경사도 업데이트를 피합니다.
Importance Sampling: 리플레이 버퍼에서
Clipping: Importance Sampling 비율과 경사도 업데이트를 Clipping하여 지나치게 큰 업데이트에 불이익을 줍니다. 이 기법을 통해 알고리즘은 KL 발산과 보상을 보다 효율적으로 절충할 수 있습니다.
Clipping 기법을 구현하는 방법에는 개별 클리핑과 결합 클리핑으로 구분되는 두 가지 방법이 있습니다. 결과 알고리즘을 쌍방향 근거리 정책 최적화(P3O) 라 하며, 변형은 각각
평가
요약과 질의응답이라는 두 가지 개방형 텍스트 생성 작업에 대해 살펴봅니다. 요약의 경우, Reddit의 포럼 게시물
우리는 알고리즘 P3O를 LLM 조정을 위한 몇 가지 효과적이고 대표적인 접근 방식과 비교합니다. 우선 최대 우도법으로 학습된 SFT 정책에서 시작합니다. RL 알고리즘의 경우, 지배적인 접근 방식인 PPO와 새로 제안된 DPO를 고려합니다. DPO는 KL 제약 RL 문제의 닫힌 형태 해를 향해 정책을 직접 최적화합니다. 오프라인 정렬 방법으로 제안되었지만 프록시 보상 함수(Proxy Reward Function)를 사용하여 온라인화합니다.
참조 정책에서 너무 많이 벗어나면 이전 연구에서 지적한 것처럼 온라인 정책이 보상 모델의 일부분을 잘라내어 일관성 없는 연속성을 만들 수 있습니다. 우리는 RL 이론에서 잘 확립된 지표인 보상뿐만 아니라 학습된 정책이 초기 정책에서 얼마나 벗어났는지를 KL-편차로 측정하는 데에도 관심이 있습니다. 따라서 달성한 보상 프론티어와 기준 정책과의 KL-편차를 기준으로 각 알고리즘의 효율성을 조사합니다(KL-Reward Frontier). 위 그림과 아래 그림을 보면, 다양한 모델 규모에 걸쳐 P3O가 PPO와 DPO보다 훨씬 우세한 프론티어를 가지고 있음을 알 수 있습니다.
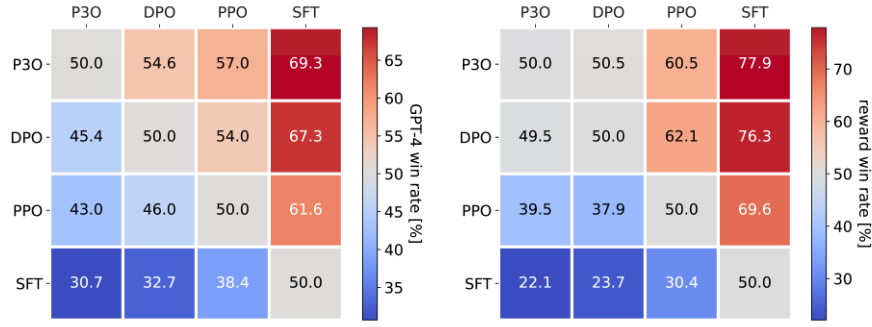
또한, 생성된 응답의 품질을 직접 평가하기 위해 HH 데이터셋의 모든 알고리즘 쌍 간에 일대일 비교를 수행합니다. 평가에는 두 가지 지표를 사용합니다. (1) 온라인 RL 중 최적화된 목표인 보상, (2) 응답 유용성에 대한 인간 평가의 충실한 대리 지표인 GPT-4입니다. 후자의 경우, 이전 연구에 따르면 GPT-4 판단은 인간과 밀접한 상관관계가 있으며, 일반적으로 GPT-4에 대한 인간의 동의는 주석자 간 동의와 비슷하거나 더 높다는 점을 보여줍니다.
위 그림은 종합적인 상호 비교 결과를 보여줍니다. 이 모델들의 평균 KL 발산 및 보상 순위는 DPO > P3O > PPO > SFT 순입니다. DPO는 보상에서 P3O를 근소하게 능가하지만, KL 발산이 상당히 높아 생성 품질에 해로울 수 있습니다. 그 결과, DPO의 보상 성공률은 P3O 대비 49.5%이지만 GPT-4에서 평가한 결과 45.4%에 불과합니다. 다른 방법과 비교했을 때, P3O는 PPO에 대해 57.0%, SFT에 대해 69.3%의 GPT-4 성공률을 보였습니다. 이 결과는 KL-보상 프론티어 지표의 결과와 일치하며, P3O가 이전 기준보다 인간의 선호도에 더 잘 부합할 수 있음을 보여줍니다.
결론
이 블로그 포스팅에서는 강화 학습을 통해 대규모 언어 모델을 인간의 선호도에 맞게 조정하는 새로운 방법을 제시합니다. 첫번째 과 같이 상대 피드백을 통한 강화 학습 프레임워크를 제안했습니다. 이 프레임워크에 따라 새로운 정책 기울기 알고리즘인 P3O를 개발했습니다. 이 접근 방식은 비교 학습을 통해 보상 모델링과 RL 미세 조정의 기본 원칙을 통합합니다. 연구 결과에 따르면 P3O는 KL-Reward 프론티어와 GPT-4 성공률 측면에서 이전 방법을 능가하는 것으로 나타났습니다.
참고자료: https://thwu1.github.io/tianhaowu/blog/2023/p3o/
Rethinking the Role of PPO in RLHF | Tianhao Wu
Rethinking the Role of PPO in RLHF Contents TL;DR: In RLHF, there’s tension between the reward learning phase, which uses human preference in the form of comparisons, and the RL fine-tuning phase, which optimizes a single, non-comparative reward. What if
thwu1.github.io



