
늦깎이 공대생의 인공지능 연구실
[논문프리뷰]Ghostbuster: 대형 언어 모델에 의해 대필된 텍스트 감지하기 본문
ChatGPT와 같은 대형 언어 모델은 놀라울 정도로 글을 잘 써서 실제 문제가 되고 있습니다. 학생들이 과제를 대필하는 데 이러한 모델을 사용하기 시작하면서 일부 학교에서는 ChatGPT를 금지하기도 했습니다. 또한 이러한 모델은 팩트에 오류가 있는 글을 생성하기 쉽기 때문에 주의 깊은 독자들은 뉴스 기사나 기타 자료를 대필하는 데 생성 AI 도구가 사용되었는지 여부를 확인한 다음 신뢰 여부를 결정해야 할 것입니다.
교수와 학생들은 무엇을 할 수 있나요? AI가 생성한 텍스트를 감지하는 기존 도구는 학습된 데이터와 다른 데이터에 대해 제대로 작동하지 않는 경우가 있습니다. 또한 이러한 모델이 실제 사람이 작성한 글을 AI가 작성한 것으로 잘못 분류할 경우, 진위 여부에 대한 의심을 받는 학생이 과제 대필에 대한 의심을 살 수도 있습니다.
최근에 발표된 논문을 통해 AI가 생성한 텍스트를 탐지하는 최첨단 방법인 Ghostbuster를 소개드리고자 합니다. Ghostbuster는 여러 약한 언어 모델에서 문서의 각 토큰이 생성될 확률을 찾은 다음, 이 확률에 기반한 함수를 최종 분류기에 입력으로 결합하는 방식으로 작동합니다. Ghostbuster는 문서를 생성하는 데 사용된 모델이나 특정 모델에서 문서가 생성될 확률을 알 필요가 없습니다. 이러한 특성 덕분에 Ghostbuster는 확률을 알 수 없는 알 수 없는 모델이나 널리 사용되는 상용 모델인 ChatGPT 및 Claude와 같은 블랙박스 모델에 의해 생성되었을 가능성이 있는 텍스트를 탐지하는 데 특히 유용합니다. 특히 고스트버스터가 원활히 범용화할 수 있도록 하기 위해 다양한 도메인(새로 수집한 에세이, 뉴스, 스토리 데이터셋 사용), 언어 모델 또는 프롬프트 등 텍스트가 생성될 수 있는 다양한 방법을 사용해 평가를 진행해 보았습니다.

이러한 접근 방식이 필요한 이유는?
오늘날의 수많은 AI 생성 텍스트 감지 시스템은 다양한 유형의 텍스트(예: 다양한 작문 방식, 다양한 텍스트 생성 모델 또는 프롬프트)를 분류하는 데 한계가 있습니다. 일반적으로 복잡한 특성(Perplexity)만을 사용하는 단순한 모델은 더 복잡한 특성을 포착하지 못하며, 특히 새로운 글쓰기 영역에서는 제대로 작동하지 않습니다. 실제로 영어가 모국어가 아닌 사용자 데이터를 포함한 일부 도메인에서는 어려움만으로 기준을 삼는 것이 무작위보다 더 못하다는 사실을 발견했습니다. 한편, RoBERTa와 같은 대규모 언어 모델에 기반한 분류기는 복잡한 특성을 쉽게 포착하지만 훈련 데이터에 오버핏되어 일반화가 제대로 이루어지지 않습니다. RoBERTa 기준점은 최악의 경우 일반화 성능이 치명적이며 때로는 어려움만을 고려한 기준점보다 더 나쁘다는 것을 발견했습니다. 레이블이 지정된 데이터에 대한 학습 없이 특정 모델에 의해 텍스트가 생성되었을 확률을 계산하여 텍스트를 분류하는 제로 샷 방법도 실제로 다른 모델이 텍스트를 생성하는 데 사용되었을 때 성능이 떨어지는 경향이 있습니다.
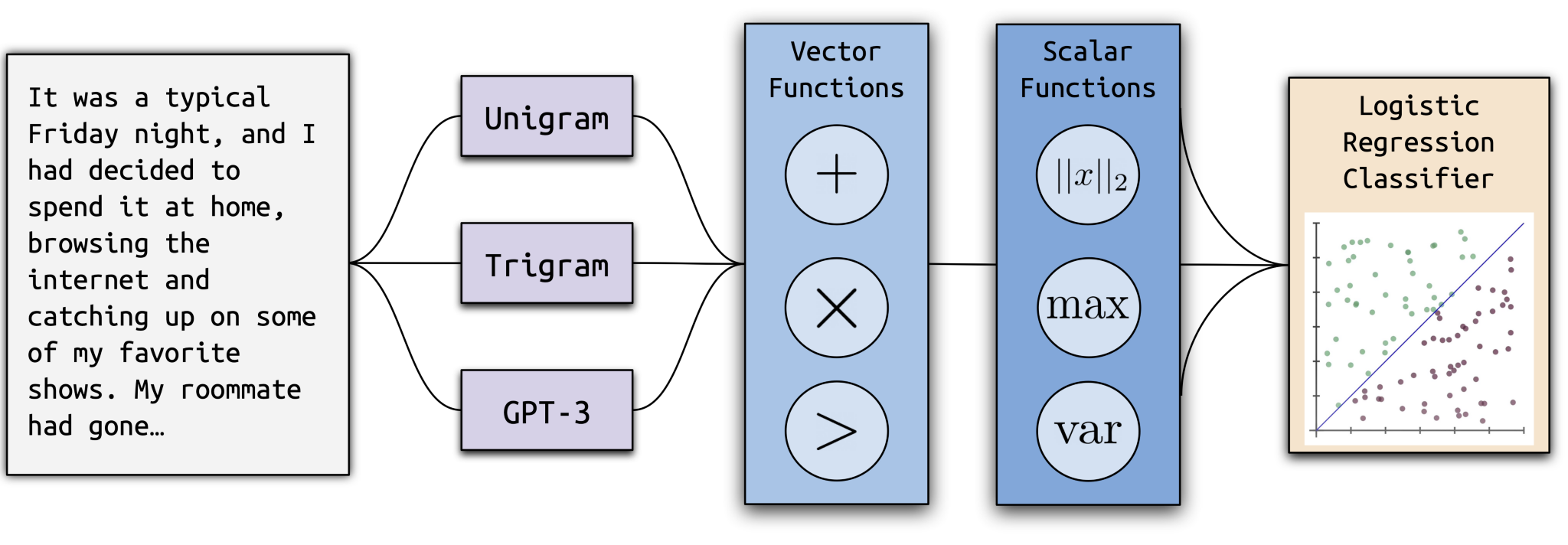
Ghostbuster 작동 방식
Ghostbuster는 확률 계산, 특성 선택, 분류기 학습의 3단계 학습 프로세스를 사용합니다.
확률 계산: 여러 가지 약한 언어 모델( Unigram 모델, Trigram 모델, 그리고 명령어 튜닝을 하지 않은 GPT-3 모델인 ada와 davinci)을 사용하여 문서에서 각 단어가 생성될 확률을 계산하여 각 문서를 일련의 벡터로 변환합니다.
특성 선택: (1) 확률을 결합하는 벡터 및 스칼라 연산 집합을 정의하고 (2) 순방향 특성 선택을 사용하여 이러한 연산의 유용한 조합을 검색하여 가장 좋은 나머지 특성을 반복적으로 추가하는 방식으로 작동하는 구조화된 검색 절차를 사용하여 특성을 선택합니다.
분류기 학습: 가장 좋은 확률 기반 특성과 수동으로 선택한 몇 가지 추가 특성에 대해 선형 분류기를 학습시킵니다.
결과
동일한 도메인에서 학습 및 테스트 결과, Ghostbuster는 세 가지 데이터셋 모두에서 99.0 F1을 달성하여 GPTZero를 5.9 F1, DetectGPT를 41.6 F1 차이로 훨씬 뛰어넘었습니다. 도메인 외부에서는 모든 조건에서 평균 97.0 F1을 달성하여 39.6 F1의 DetectGPT와 7.5 F1의 GPTZero보다 우수한 성능을 보였습니다. 모든 데이터셋에 대해 도메인 내에서 평가했을 때 RoBERTa 기준치는 98.1 F1을 달성했지만 일반화 성능은 일정하지 않았습니다. Ghostbuster는 도메인 이외의 창의적 글쓰기를 제외한 모든 영역에서 RoBERTa 기준치를 능가했으며, 평균적으로 RoBERTa보다 훨씬 더 나은 도메인 이외의 성능을 보였습니다(13.8 F1 차이).

다양한 글쓰기 스타일이나 읽기 수준을 요청하는 등 사용자가 모델에 프롬프트를 보낼 수 있는 다양한 방식에 대해 얼마나 견고한지 확인하기 위해 여러 가지 프롬프트 변형에 대한 Ghostbuster의 견고성을 평가했습니다. Ghostbuster는 99.5 F1으로 이러한 프롬프트 변형에 대해 테스트한 다른 모든 접근 방식보다 뛰어난 성능을 보였습니다. 모델 간 일반화를 테스트하기 위해 Claude가 생성한 텍스트에 대한 성능을 평가한 결과, Ghostbuster는 92.2 F1으로 테스트한 다른 모든 접근 방식보다 우수한 성능을 보였습니다.
AI로 생성된 텍스트 감지기는 생성된 텍스트를 가볍게 편집하여 속일 수 있습니다. 문장이나 단락 바꾸기, 문자 순서 바꾸기, 단어를 동의어로 바꾸기 등의 편집에 대한 Ghostbuster의 견고성을 테스트했습니다. 문장이나 단락 수준에서의 대부분의 변화는 성능에 큰 영향을 미치지 않았지만, 반복적인 의역을 통해 텍스트를 편집하거나, 탐지 불가능한 AI와 같은 상용 탐지 회피 프로그램을 사용하거나, 단어 또는 문자 수준을 많이 변경하는 경우 성능이 원활하게 저하되었습니다. 성능은 또한 장문의 문서에서 가장 우수했습니다.
AI 생성 텍스트 감지기는 영어가 모국어가 아닌 사용자의 텍스트를 AI가 생성한 것으로 잘못 분류할 수 있기 때문에, 영어가 모국어가 아닌 사용자의 글에 대한 Ghostbuster의 성능을 평가했습니다. 테스트한 모든 모델은 세 가지 데이터셋 중 두 가지 데이터셋에서 95% 이상의 정확도를 보였지만, 짧은 에세이로 구성된 세 번째 데이터셋에서는 정확도가 떨어졌습니다. 그러나 장문의 문서(74.7 F1)에서도 비슷한 수준의 다른 도메인 외부 문서(75.6~93.1 F1)와 거의 동일한 성능을 보였기 때문에 여기서는 문서 길이가 주요 요인일 수 있습니다.
Ghostbuster를 텍스트 생성이 허용되지 않는 실제 사례(예: ChatGPT로 작성된 학생 에세이)에 적용하려는 사용자는 짧은 텍스트, Ghostbuster가 학습한 것과는 다른 도메인(예: 다양한 유형의 영어), 영어가 모국어가 아닌 사용자가 작성한 텍스트, 사람이 편집한 모델 생성 텍스트 또는 사람이 작성한 입력을 AI 모델에 수정하도록 요청하여 생성한 텍스트에서 오류가 발생할 가능성이 더 높다는 점에 유의해야 합니다. 알고리즘의 지속적인 피해를 방지하기 위해, 사람의 지도 감독 없이 텍스트 생성 행위가 의심되는 경우 자동으로 불이익을 주는 것은 강력히 권장하지 않습니다. 대신, 다른 사람의 글을 AI가 생성한 것으로 분류하는 것이 해당 사용자에게 해를 끼칠 수 있는 경우 신중하게 사람이 직접 Ghostbuster를 사용할 것을 권합니다. 또한 Ghostbuster는 언어 모델 학습 데이터에서 AI 생성 텍스트를 필터링하고 온라인 정보 출처가 AI 생성인지 확인하는 등 위험도가 낮은 다양한 분야에 도움을 줄 수 있습니다.
결론
Ghostbuster는 테스트된 도메인에서 99.0 F1의 성능을 보이는 최첨단 AI 생성 텍스트 감지 모델로, 기존 모델에 비해 상당한 발전을 이루었습니다. 다양한 도메인, 프롬프트 및 모델에 대해 일반화가 가능하며, 문서 생성에 사용된 특정 모델의 확률에 접근할 필요가 없기 때문에 블랙박스 또는 알 수 없는 모델의 텍스트를 식별하는 데 매우 적합합니다.
Ghostbuster의 향후 방향은 모델 결정에 대한 설명을 제공하고 탐지기를 속이려는 공격에 대한 견고성을 개선하는 것입니다. AI로 생성된 텍스트 탐지 접근 방식은 워터마킹과 같은 대안과 함께 사용할 수도 있습니다. 또한 언어 모델 학습 데이터를 필터링하거나 웹에서 AI가 생성한 콘텐츠에 플래그를 지정하는 등 다양한 분야에서 Ghostbuster가 도움이 될 수 있기를 기대합니다.
참고자료: https://arxiv.org/abs/2305.15047
Ghostbuster: Detecting Text Ghostwritten by Large Language Models
We introduce Ghostbuster, a state-of-the-art system for detecting AI-generated text. Our method works by passing documents through a series of weaker language models, running a structured search over possible combinations of their features, and then traini
arxiv.org



