
늦깎이 공대생의 인공지능 연구실
[논문프리뷰]명령어에 맞는 목표 시각화(Goal Representations for Instruction Following) 본문
[논문프리뷰]명령어에 맞는 목표 시각화(Goal Representations for Instruction Following)
Justin T. 2023. 11. 4. 23:36
로봇 학습 분야의 오랜 목표는 인간을 대신해 작업을 수행할 수 있는 범용 에이전트를 만드는 것이었습니다. 자연어는 인간이 임의의 작업을 지정할 수 있는 사용하기 쉬운 인터페이스가 될 수 있는 잠재력을 가지고 있지만, 로봇이 언어 명령어를 따르도록 훈련하기는 어렵습니다. 언어 조건부 행동 복제(Language-Conditioned Behavioral Cloning)와 같은 접근 방식은 언어에 기반한 전문가의 행동을 직접 모방하도록 정책을 학습시키지만, 사람이 모든 학습 경로에 주석을 달아야 하고 여러 장면과 행동에 걸쳐 일반화가 잘 되지 않는 단점이 있습니다. 한편, 최근의 목표 조건부 접근 방식은 일반적인 조작 작업에서는 훨씬 더 나은 성능을 보이지만, 인간 작업자가 작업을 쉽게 지정할 수 없습니다. LCBC와 같은 정보 접근 방식을 통한 작업 지정의 용이성과 목표 조건부 학습의 성능 향상을 적절하게 조화시킬 수 있는 방법은 무엇일까요?
개념적으로 명령어를 따르는 로봇에는 두 가지 능력이 필요합니다. 언어 명령어와 물리적 환경을 기반으로 하고, 의도한 작업을 완료하기 위해 일련의 작업을 수행할 수 있어야 합니다. 이러한 기능은 사람이 주석을 단 경로만으로 처음부터 끝까지 학습할 필요 없이 적절한 데이터 소스로부터 개별적으로 학습할 수 있습니다. 로봇이 아닌 소스의 비전 언어 데이터는 다양한 명령어와 시각 장면에 일반화하여 언어의 기초를 학습하는 데 도움이 될 수 있습니다. 한편, 레이블이 지정되지 않은 로봇 경로를 사용하여 언어 명령어와 관련이 없는 경우에도 특정 목표 상태에 도달하도록 로봇을 학습시킬 수 있습니다.
시각적 목표( 예: 목표 이미지)에 대한 조건화는 정책 학습에 보완적인 이점을 제공합니다. 목표는 작업 사양의 한 형태로서, 나중에 자유롭게 레이블을 다시 지정할 수 있기 때문에 확장에 적합합니다( 경로를 따라 도달한 모든 상태가 목표가 될 수 있음). 따라서 로봇이 자율적으로 수집한 데이터를 포함하여 주석이 달리지 않은 대량의 비정형 궤적 데이터에 대해 목표 조건부 행동 복제( Goal-Conditioned Behavioral Cloning )를 통해 정책을 학습할 수 있습니다. 또한 목표는 이미지로서 다른 상태와 픽셀 단위로 직접 비교할 수 있으므로 근거를 마련하기가 더 쉽습니다.
그러나 목표는 자연어보다 인간 사용자에게는 덜 직관적입니다. 대부분의 경우, 사용자가 수행하고자 하는 작업을 설명하는 것이 목표 이미지를 제공하는 것보다 더 쉬우며, 이미지를 생성하기 위해서는 어쨌든 작업을 수행해야 할 가능성이 높습니다. 목표 조건부 정책을 위한 언어 인터페이스를 노출함으로써 목표와 언어 작업 사양의 강점을 결합하여 쉽게 명령할 수 있는 범용 로봇을 구현할 수 있습니다. 아래에서 설명하는 방법은 이러한 인터페이스를 노출하여 시각 언어 데이터를 사용하여 다양한 명령어와 장면에 일반화하도록 하고, 대규모 비정형 로봇 데이터셋을 소화하여 물리적 기술을 향상시킵니다.
명령어에 맞는 목표 시각화(Goal Representations for Instruction Following)
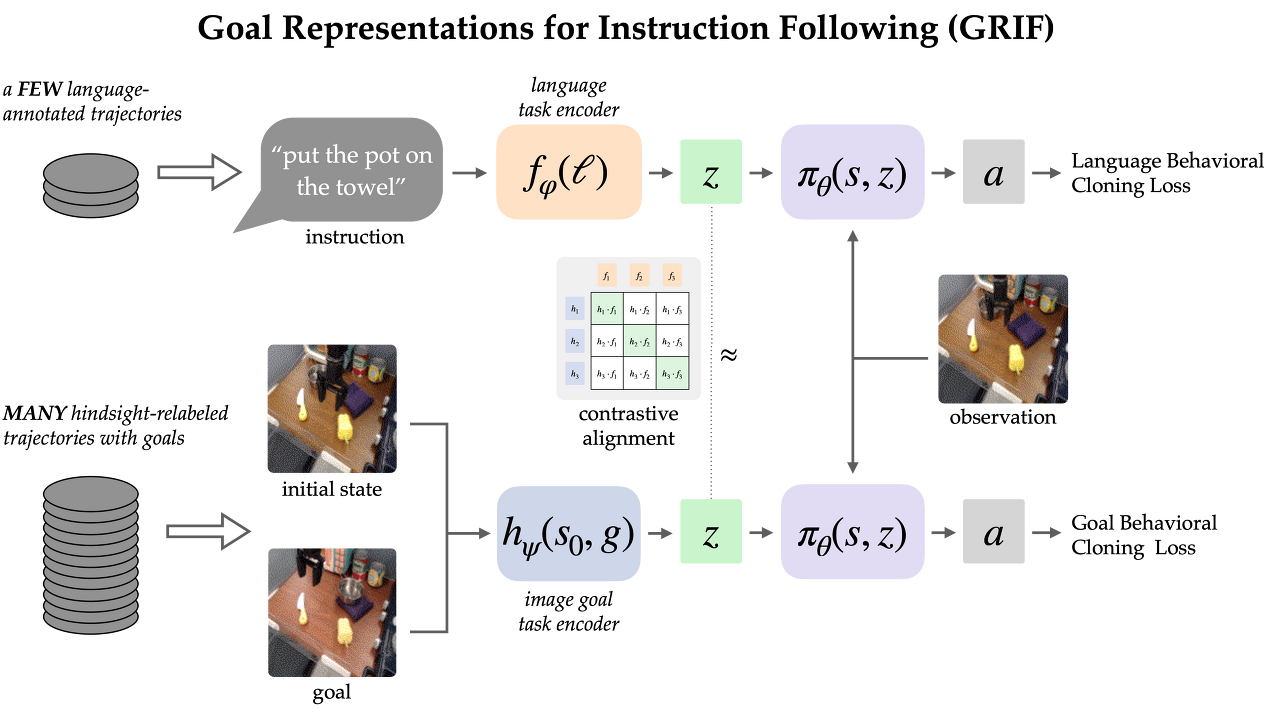
우리의 접근 방식인 GRIF(Goal Representations for Instruction Following)는 언어 조건부 정책(Language-Conditioned Policy)과 목표 조건부 정책(Goal-Conditioned Policy)을 함께 학습하고 작업 표현을 정렬합니다. 언어와 목표 양식에 걸쳐 정렬된 이러한 표현을 통해 목표 조건부 학습의 이점을 언어 조건부 정책과 효과적으로 결합할 수 있다는 것이 핵심 내용입니다. 학습된 정책은 대부분 레이블이 지정되지 않은 데모 데이터로 학습한 후 여러 언어와 장면에 걸쳐 범용화할 수 있습니다.
우리는 주방 조작 환경에서 label이 지정된 데모 7,000개의 경로와 label이 지정되지 않은 경로 47,000개가 포함된 Bridge-v2 데이터셋 버전으로 GRIF를 학습시켰습니다. 이 데이터셋의 모든 경로를 사람이 수동으로 주석을 달아야 했기 때문에 주석 없이 47,000개의 경로를 직접 사용할 수 있게 되어 효율성을 크게 개선할 수 있었습니다.
두 가지 유형의 데이터로부터 학습하기 위해 GRIF는 언어 조건부 행동 복제(LCBC) 및 목표 조건부 행동 복제(GCBC)와 함께 학습됩니다. 레이블이 지정된 데이터셋에는 언어와 목표 작업 사양이 모두 포함되어 있으므로 언어 및 목표 조건부 예측(즉, LCBC 및 GCBC)을 모두 지도하는 데 사용합니다. 레이블이 지정되지 않은 데이터셋은 목표만 포함하며 GCBC에 사용됩니다. LCBC와 GCBC의 차이는 해당 인코더에서 작업 표현을 선택하는 것의 문제일 뿐이며, 이는 공유 정책 네트워크로 전달되어 행동을 예측합니다.
정책 네트워크를 공유하면 목표 조건 학습에 레이블이 지정되지 않은 데이터셋을 사용함으로써 약간의 개선을 기대할 수 있습니다. 그러나 GRIF는 일부 언어 명령어와 목표 이미지가 동일한 행동을 지정한다는 점을 인식하여 두 양식 간에 훨씬 더 강력한 전이를 가능하게 합니다. 특히 동일한 의미적 작업에 대해 언어와 목표 표현이 유사해야 한다는 점에서 이 구조를 활용합니다. 이 구조가 유지된다고 가정하면, 레이블이 없는 데이터는 목표 표현이 누락된 명령어의 표현과 근사화되므로 언어 조건부 정책에도 도움이 될 수 있습니다.
대조 학습을 통한 조정(Alignment through Contrastive Learning)

언어는 종종 상대적인 변화를 설명하기 때문에, 우리는 상태-목표 쌍의 표현을 언어 명령어와 일치하도록 선택합니다(단순히 목표를 언어와 일치시키는 것과는 반대로). 경험적으로, 이렇게 하면 이미지에서 대부분의 정보를 생략하고 상태와 목표 사이의 변화에 집중할 수 있기 때문에 표현을 더 쉽게 학습할 수 있습니다.
우리는 레이블이 지정된 데이터셋의 명령어와 이미지에 대한 infoNCE 목표를 통해 이러한 조정 구조를 학습합니다. 언어와 목표 표현의 일치 쌍에 대해 대조 학습을 수행하여 이중 이미지 및 텍스트 인코더를 학습시킵니다. 이 목표는 동일한 작업에 대한 표현 간에는 높은 유사성을, 다른 작업에 대해서는 낮은 유사성을 유도하며, 부정적인 예시들은 다른 경로에서 샘플링됩니다.
순수 네거티브 샘플링(나머지 데이터셋과 균일한)을 사용할 때 학습된 표현은 종종 실제 작업을 무시하고 동일한 장면을 참조하는 명령어와 목표를 단순히 정렬하는 경우가 많았습니다. 실제 세계에서 이 정책을 사용하려면 언어를 장면과 연관시키는 것은 그다지 유용하지 않으며, 오히려 같은 장면에서 서로 다른 작업을 구분하는 데 필요합니다. 따라서 같은 장면에서 서로 다른 경로를 통해 최대 절반의 네거티브를 샘플링하는 Hard Negative Sampling 전략을 사용합니다.
이러한 대조적인 학습 설정은 당연히 CLIP과 같이 사전 학습된 시각 언어 모델을 방해합니다. 이 모델은 시각 언어 작업에 효과적인 zero-shot 및 few-shot 일반화 성능을 보여주며, 인터넷 규모의 사전 학습에서 얻은 지식을 통합할 수 있는 방법을 제공합니다. 그러나 대부분의 시각 언어 모델은 환경의 변화를 이해하는 기능 없이 하나의 정적 이미지를 캡션에 맞추기 위해 설계되었으며, 복잡한 장면에서 하나의 객체에 주의를 기울여야 할 때 성능이 저하됩니다.
이러한 문제를 해결하기 위해 작업 표현을 정렬하기 위해 CLIP을 수용하고 미세 조정하는 메커니즘을 고안했습니다. 초기 융합(채널 단위로 스택)과 결합된 한 쌍의 이미지에서 작동할 수 있도록 CLIP 아키텍처를 수정합니다. 이는 상태 이미지와 목표 이미지 쌍을 인코딩하는 데 적합한 초기화 방식이며, 특히 CLIP의 사전 학습 이점을 보존하는 데 탁월한 것으로 밝혀졌습니다.
로봇 정책 결과
주요 결과를 알아보기 위해 3개의 장면에 걸쳐 15개의 작업에 대해 현실 세계의 GRIF 정책을 평가합니다. 주어진 명령어는 학습 데이터에 잘 표현된 명령어와 어느 정도의 구성 일반화가 필요한 새로운 명령어를 혼합하여 선택했습니다. 장면 중 하나에는 보이지 않는 물체의 조합도 포함되어 있습니다.
GRIF를 일반 LCBC와 LangLfP 및 BC-Z와 같은 이전 작업에서 영감을 얻은 더 강력한 기준과 비교합니다. LLfP는 LCBC 및 GCBC와의 결합 학습을 의미합니다. BC-Z는 이름에서 따온 방법을 우리 환경에 맞게 변형한 것으로, LCBC, GCBC 및 간단한 정렬 용어로 학습합니다. 이 방법은 작업 표현 간의 코사인 거리 손실을 최적화하고 이미지 언어 사전 학습을 사용하지 않습니다.
이 정책은 두 가지 주요 실패 모드에 취약했습니다. 언어 명령어를 이해하지 못해 다른 작업을 시도하거나 유용한 작업을 전혀 수행하지 못할 수 있습니다. 언어 기반이 견고하지 않은 경우, 원래 명령어가 문맥에 맞지 않기 때문에 정책이 올바른 작업을 수행한 후 의도하지 않은 작업을 수행할 수도 있습니다.
작업 실패 예시
 |
 |
 |
 |
| "버섯을 금속 냄비에 넣으세요" |
"숟가락을 수건에 올려놓으세요" |
"노란 피망을 천에 올려놓으세요" |
"노란 피망을 천에 올려놓으세요" |
다른 실패 모드는 물체를 조작하지 못하는 경우입니다. 이는 물체를 놓치거나, 부정확하게 움직이거나, 잘못된 타이밍에 물체를 놓치기 때문일 수 있습니다. 전체 데이터셋에 대해 학습된 GCBC 정책은 일관되게 조작에 성공할 수 있으므로 이러한 오류는 로봇 설정의 본질적인 단점이 아닙니다. 오히려 이러한 실패 모드는 일반적으로 목표 조건 데이터를 활용하는 데 비효율적이라는 것을 나타냅니다.
조작 실패 예시
 |
 |
 |
| "피망을 테이블 왼쪽으로 옮기세요" | "피망을 팬에 넣으세요" | "수건을 전자레인지 옆으로 옮기세요" |
두 기준을 비교해보면, 이 두 가지 실패 모드가 각각 다른 정도에서 발생했습니다. LCBC는 레이블이 지정된 작은 경로 데이터셋에만 의존하며, 조작 능력이 떨어져 어떤 작업도 완료하지 못합니다. LLfP는 레이블이 지정된 데이터와 레이블이 지정되지 않은 데이터에 대해 함께 정책을 훈련하며 LCBC보다 크게 향상된 조작 능력을 보여줍니다. 일반적인 명령어에 대해서는 합리적인 성공률을 달성하지만 더 복잡한 명령어에 대해서는 실패합니다. BC-Z의 정렬 전략도 조작 능력을 향상시키는데, 이는 정렬이 모달리티 간 전송을 개선하기 때문인 것으로 보입니다. 그러나 외부 시각 언어 데이터 소스가 없으면 새로운 명령어로 일반화하는 데 여전히 어려움을 겪습니다.
GRIF는 강력한 조작 능력을 갖추고 있으면서도 가장 뛰어난 범용화를 보여줍니다. 장면에서 여러 가지 작업이 가능한 경우에도 언어 명령어를 기반으로 작업을 수행할 수 있습니다. 아래에 몇 가지 활용 사례와 해당 명령어가 나와 있습니다.
GRIF의 정책 적용
 |
 |
 |
 |
| "팬을 앞으로 옮기세요" | "피망을 팬에 넣으세요" | "보라색 천에 칼을 올려놓으세요" |
"숟가락을 수건에 올려놓으세요" |
결론
GRIF를 사용하면 로봇이 대량의 레이블이 없는 경로 데이터를 활용하여 목표 조건부 정책을 학습할 수 있으며, 정렬된 언어-목표 작업 표현을 통해 이러한 정책에 대한 '언어 인터페이스'를 제공할 수 있습니다. 이전의 언어-이미지 정렬 방법과 달리, 우리의 표현은 상태의 변화를 언어에 정렬하며, 이는 표준 CLIP 스타일의 이미지-언어 정렬 목표에 비해 상당한 개선을 이끌어냅니다. 실험을 통해 우리의 접근 방식이 레이블이 없는 로봇 경로를 효과적으로 활용할 수 있으며, 언어 주석이 달린 데이터만 사용하는 기준과 방법보다 성능이 크게 개선되었음을 입증했습니다.
이 방법에는 향후 작업에서 해결할 수 있는 여러 가지 한계가 있습니다. GRIF는 무엇을 해야 하는 것보다 어떻게 해야 하는지에 대한 명령어(예: "물을 천천히 부으세요")가 더 많은 작업에는 적합하지 않습니다. 이러한 정성적 명령어에는 작업 실행의 중간 단계를 고려하는 다른 유형의 정렬 손실이 필요할 수 있습니다. 또한 GRIF는 모든 언어 기준이 완전히 주석이 달린 데이터셋의 일부 또는 사전 학습된 VLM에서 나온다고 가정합니다. 향후 흥미로운 연구 방향은 인터넷 규모의 데이터에서 풍부한 의미를 학습하기 위해 인간의 비디오 데이터를 활용하도록 정렬 손실을 확장하는 것입니다. 이러한 접근 방식은 이 데이터를 사용하여 로봇 데이터셋 외부의 언어에 대한 기초를 개선하고 사용자 명령어에 따라 광범위하게 범용화할 수 있는 로봇 정책을 구현할 수 있습니다.
참고자료: https://arxiv.org/abs/2307.00117
Goal Representations for Instruction Following: A Semi-Supervised Language Interface to Control
Our goal is for robots to follow natural language instructions like "put the towel next to the microwave." But getting large amounts of labeled data, i.e. data that contains demonstrations of tasks labeled with the language instruction, is prohibitive. In
arxiv.org



