
늦깎이 공대생의 인공지능 연구실
[논문프리뷰] 전신 기반 에고센트릭 비디오 예측 (Whole-Body Conditioned Egocentric Video Prediction) 본문
[논문프리뷰] 전신 기반 에고센트릭 비디오 예측 (Whole-Body Conditioned Egocentric Video Prediction)
Justin T. 2026. 1. 12. 02:11
이 논문은 PEVA(Predict Ego-centric Video from human Actions)라는 모델을 훈련하여, 전신(whole-body) 동작을 조건으로 하는 에고센트릭(1인칭 시점) 비디오 예측을 수행했습니다. PEVA는 신체 관절의 계층 구조로 구조화된 운동학적(kinematic) 포즈 궤적을 조건으로 받아, 인간의 물리적 행동이 1인칭 시점에서 환경을 어떻게 변화시키는지를 시뮬레이션하도록 학습합니다. 이 논문은 실제 에고센트릭 비디오와 신체 포즈 캡처가 쌍으로 이루어진 대규모 데이터셋인 Nymeria를 사용하여, 자기회귀적 조건부 디퓨전 트랜스포머(autoregressive conditional diffusion transformer)를 훈련했습니다. 또한 점점 더 어려워지는 과제들로 구성된 계층적 평가 프로토콜을 설계하여, 모델의 신체화된(embodied) 예측 및 제어 능력을 포괄적으로 분석했습니다.
PEVA: 인간 행동으로부터 에고센트릭 비디오 예측하기

최근 몇 년 동안 계획(planning)과 제어(control)를 위해 미래 결과를 시뮬레이션하는 세계 모델(world models) 분야에서 상당한 발전이 있었습니다. 직관적 물리학(intuitive physics)에서부터 다단계 비디오 예측에 이르기까지, 이러한 모델들은 점점 더 강력해지고 표현력이 풍부해졌습니다.
그러나 진정한 의미의 신체화된 에이전트(Embodied Agents)를 위해 설계된 모델은 거의 없었습니다. 신체화된 에이전트를 위한 세계 모델을 만들기 위해서는 실제 세계에서 행동하는 실제 에이전트를 고려해야 합니다. 실제 신체화된 에이전트는 추상적인 제어 신호가 아닌 물리적으로 기반을 둔 복잡한 행동 공간(action space)을 가집니다. 또한 그들은 미적으로 연출된 장면이나 고정된 카메라가 아닌, 다양한 실제 시나리오 속에서 에고센트릭(1인칭) 시점을 통해 행동해야 합니다.

신체화된 에이전트 구현이 어려운 이유
사람처럼 보고, 생각하고 움직이는 신체화된 에이전트를 만드는 일은 매우 어렵습니다. 그 이유는 다음과 같습니다.
- 행동과 비전의 강한 맥락 의존성(Action and vision are heavily context-dependent): 똑같은 장면을 보더라도 어떤 행동을 해야 할지는 상황에 따라 완전히 다릅니다. 예를 들어, 앞에 컵이 놓여 있다고 해도, 물을 마시려는 상황인지, 치우려는 상황인지에 따라 손의 움직임이 달라집니다. 반대로, 같은 행동이더라도 보는 상황이 다르면 전혀 다른 의미를 가질 수 있습니다. 이처럼 행동과 시각 정보는 상황(맥락)에 매우 의존적입니다.
- 인간 제어의 다차원성 및 구조적 특성(Human control is high-dimensional and structured): 사람의 신체는 수십 개의 관절을 가지고 있어서, 아주 다양한 방식으로 움직일 수 있습니다. 또한 움직임은 단순히 하나하나 조정되는 것이 아니라, 시간에 따라 유기적으로 연결되고 구조적으로 구성돼 있습니다. 예를 들어, 손을 뻗는 동작만 해도 어깨, 팔꿈치, 손목까지 연동해서 움직여야 하죠.
- 1인칭 시점의 의도 노출 및 신체 가려짐 특성(Egocentric view reveals intention but hides the body): 사람의 시선(1인칭 시점)에서는 어디를 보거나 어떤 목표를 원하는지는 잘 나타나지만, 자기 몸이 직접적으로 보이진 않아서 어떤 행동을 하고 있는지는 잘 알 수 없습니다. 즉, 의도는 보이지만 실제 움직임은 가려져 있는 경우가 많습니다. 인공지능 모델이 이런 영상을 보고 어떤 행동이 이루어졌는지 정확히 이해하는 건 쉽지 않습니다.
- 지각의 행동 대비 지연 현상(Perception lags behind action): 어떤 행동을 하면, 그 결과(예: 컵에 물이 채워지는 모습)는 몇 초 후에 시각적으로 나타납니다. 그래서 에이전트가 제대로 배우려면, 지금의 행동이 나중에 어떤 결과로 이어지는지를 예측할 수 있어야 합니다. 즉, 장기적인 시간 개념과 예측 능력이 필요합니다.
신체화된 에이전트를 위한 세계 모델을 개발하기 위해서는 이러한 기준을 충족하는 에이전트에 기반을 두어야 합니다. 인간은 일상적으로 먼저 보고 나중에 행동합니다. 우리의 눈은 목표에 고정되고, 뇌는 결과에 대한 짧은 시각적 "시뮬레이션"을 실행한 뒤에야 움직입니다.
주요 업무

전신 동작 기반 자아중심(Egocentric) 비디오 예측을 위한 PEVA(Predict Ego-centric Video from human Actions) 모델을 학습시켰습니다. PEVA는 신체 관절 계층 구조로 정리된 운동학적 포즈 궤적(kinematic pose trajectory)을 조건으로 삼아, 물리적인 인간 동작이 1인칭 시점에서 환경을 어떻게 변화시키는지 시뮬레이션하는 법을 학습합니다. 이 논문은 실세계 자아중심 비디오와 신체 포즈 캡처 데이터가 쌍을 이루는 대규모 데이터셋 Nymeria를 활용하여 자회귀적 조건부 디퓨전 트랜스포머(autoregressive conditional diffusion transformer)를 학습시켰습니다. 계층적 평가 프로토콜을 통해 점차 어려워지는 과제들을 테스트함으로써, 모델의 구체화된(embodied) 예측 및 제어 능력을 종합적으로 분석하였습니다. 본 연구는 인간 관점의 비디오 예측을 통해 복잡한 실세계 환경과 구체화된 에이전트 행동을 모델링하려는 초기 시도였습니다.
방법
동작에서 구조화된 행동 표현 (Structured Action Representation from Motion)
인간의 움직임과 자아중심 시각을 연결하기 위해, 각 동작을 전신 역학(full-body dynamics)과 세부 관절 움직임을 모두 포착하는 풍부한 고차원 벡터로 표현합니다. 단순화된 제어 신호 대신, 신체 운동학 트리(kinematic tree)를 기반으로 전역 이동(global translation)과 상대 관절 회전(relative joint rotations)을 인코딩합니다. 움직임은 3D 공간에서 표현되며, 루트 이동에 3 자유도, 상체 15개 관절에 대해 각각 3 자유도를 갖습니다. 상대 관절 회전에 오일러 각(Euler angles)을 사용하면 48차원 행동 공간(3 + 15 × 3 = 48)이 됩니다. 모션 캡처 데이터는 타임스탬프를 기준으로 비디오와 정렬된 후, 위치 및 방향 불변성을 위해 골반 중심의 로컬 좌표계로 변환됩니다. 모든 위치와 회전은 정규화되어 안정적인 학습이 이루어지도록 합니다. 각 행동은 프레임 간 움직임 변화를 포착하므로, 모델이 시간에 걸쳐 물리적 움직임과 시각적 결과를 연결할 수 있습니다.
PEVA 설계: 자회귀적 조건부 디퓨전 트랜스포머(Autoregressive Conditional Diffusion Transformer)

Navigation World Models의 CDiT는 속도·회전과 같은 단순 제어 신호를 사용하지만, 전신 인간 동작을 모델링하는 것은 훨씬 더 어려운 과제입니다. 인간 행동은 고차원,시간적으로 길고,물리적으로 제약이 많기 때문입니다. 이를 해결하기 위해 CDiT를 다음과 같이 3가지 방식으로 확장하였습니다.
- 무작위 타임스킵(Random Timeskips): 단기 운동 역학과 장기 활동 패턴을 모두 학습할 수 있도록 합니다.
- 시퀀스 수준 학습(Sequence-Level Training): 각 프레임 prefix에 손실을 적용하여 전체 동작 시퀀스를 모델링합니다.
- 행동 임베딩(Action Embeddings): 시간 t의 모든 행동을 1D 텐서로 연결하여 고차원 전신 동작을 각 AdaLN 레이어에 조건으로 제공합니다.
비디오 생성 및 확장 전략 (Sampling and Rollout Strategy)
테스트 단계에서는 과거의 장면들을 힌트 삼아 미래의 장면을 그려내는데, 먼저 과거 장면들을 컴퓨터가 이해하기 쉬운 핵심 정보(잠재 상태)로 요약한 뒤 목표 장면에 섞인 노이즈를 단계적으로 걷어내며 선명한 그림을 완성하고, 작업 속도를 높이기 위해 꼭 필요한 부분에만 시선을 집중(어텐션 제한)하며, 다음 행동을 예측할 때는 마치 이어달리기를 하듯 현재 행동을 반영해 바로 다음 장면을 만들고 그 장면을 다시 새로운 힌트로 써서 그다음 장면을 예측하는 과정을 반복한 후, 최종적으로 요약된 정보를 우리가 볼 수 있는 실제 화면으로 되돌려 놓습니다.
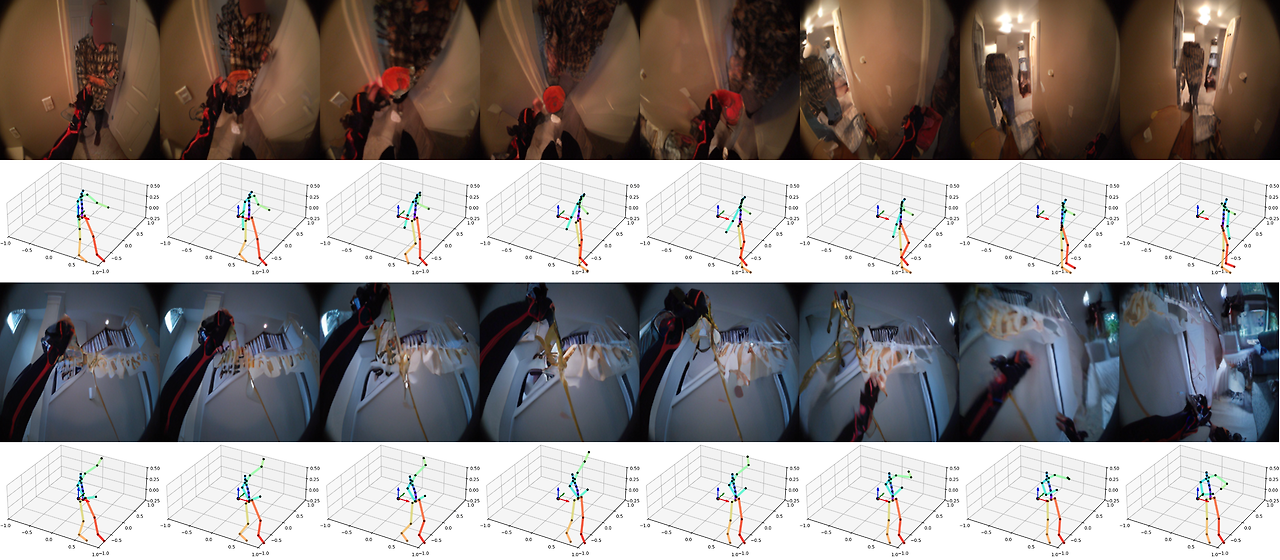
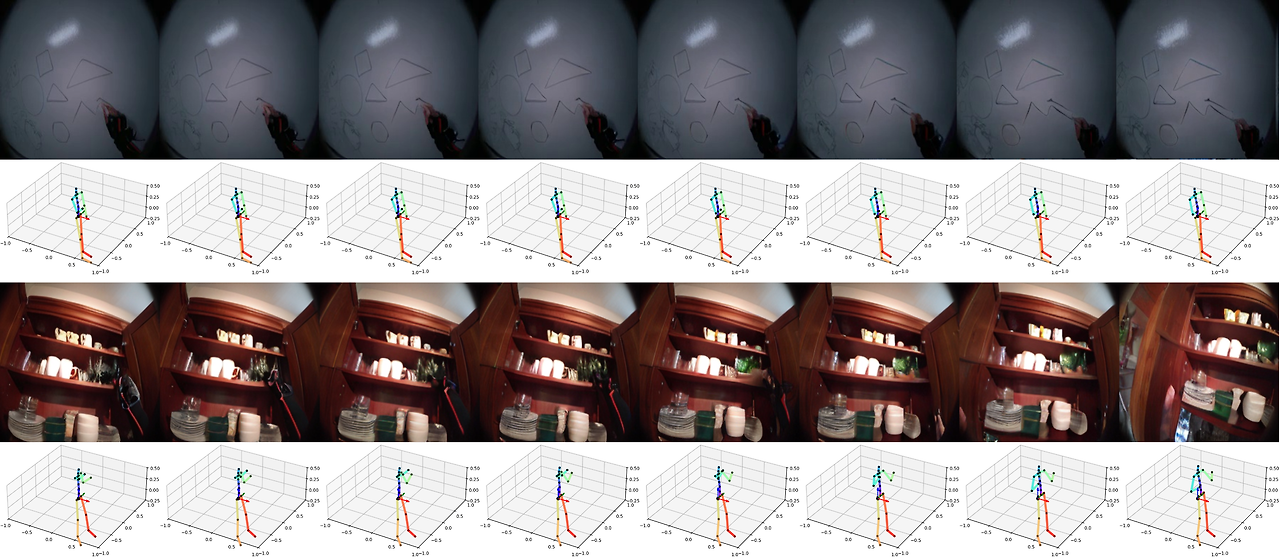
원자적 행동 (Atomic Actions)
복잡한 인간 움직임을 손 움직임(위·아래·왼쪽·오른쪽)과 전신 움직임(전진·좌회전·우회전) 등 원자적 행동(atomic actions)으로 분해하여, 특정 관절 수준 움직임이 자아중심 시야에 미치는 영향을 모델이 얼마나 이해하는지 테스트하였습니다.
| 전신 움직임 | ||
 |
 |
 |
| 전진하기 | 왼쪽으로 회전하기 | 오른쪽으로 회전하기 |
| 왼손 동작 | |
 |
 |
| 왼손 위로 올리기 | 왼손 아래로 내리기 |
 |
 |
| 왼손 왼쪽 움직이기 | 왼손 오른쪽으로 움직이기 |
| 오른손 동작 | |
 |
 |
| 오른손 위로 올리기 | 오른손 아래로 내리기 |
 |
 |
| 오른손 왼쪽으로 움직이기 | 오른손 오른쪽으로 움직이 |
장시간 롤아웃 (Long Rollout)
16초에 달하는 긴 예측 구간에서도 시각적·의미적 일관성을 유지하는 모델의 능력을 확인할 수 있습니다. 전신 동작을 조건으로 한 PEVA의 일관된 롤아웃 샘플을 비디오와 이미지로 제공합니다.
 |
 |
 |
| Sequence1 | Sequence2 | Sequence3 |
계획 수립 (Planning)
PEVA는 여러 후보 행동을 시뮬레이션한 뒤, 목표 이미지와의 지각적 유사도(LPIPS)를 기준으로 점수를 매겨 계획에 활용할 수 있습니다.


시각적 계획 능력 구현
계획 문제를 에너지 최소화 문제로 정식화하고, Navigation World Models에서 소개된 교차 엔트로피 방법(Cross-Entropy Method, CEM)을 사용하여 행동 최적화를 수행합니다. 왼쪽 또는 오른쪽 팔만 움직이도록 최적화하고 나머지 신체 부위는 고정합니다. 대표적인 계획 결과는 다음과 같습니다.
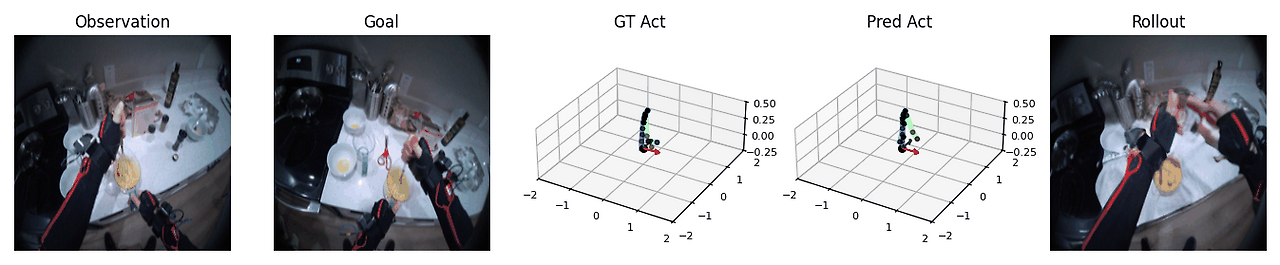
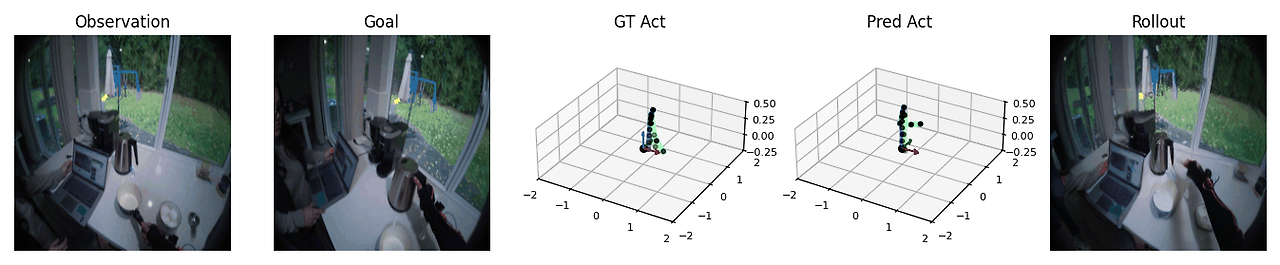

정량적 결과 (Quantitative Results)
PEVA는 여러 지표에서 전신 행동으로부터 고품질 자아중심 비디오를 생성하는 데 탁월한 성능을 보였습니다. 베이스라인을 지속적으로 능가하며, 장시간 일관성을 유지하고 모델 크기에 따라 성능이 잘 확장됩니다.
기준 인지 측정 지표

원자적 행동 성능

FID 비교

스케일링

향후 방향 (Future Directions)
본 모델은 전신 동작으로부터 자아중심 비디오를 예측하는 데 유망한 결과를 보여주었으나, 구체화된 계획(embodied planning)을 향한 초기 단계에 불과합니다. 현재 계획은 팔 동작 후보 시뮬레이션에 국한되며 장기 계획이나 전체 궤적 최적화는 부족합니다. PEVA를 폐루프 제어(closed-loop control)나 상호작용 환경으로 확장하는 것이 중요한 다음 단계입니다. 현재는 작업 의도나 의미적 목표에 대한 명시적 조건이 없고, 이미지 유사도를 대리 목표로 사용하고 있습니다. 향후 연구에서는 고수준 목표 조건 추가, 객체 중심 표현(object-centric representation) 통합 등을 통해 PEVA를 더욱 발전시킬 수 있을 것입니다.
참고자료: https://arxiv.org/abs/2506.21552
Whole-Body Conditioned Egocentric Video Prediction
We train models to Predict Ego-centric Video from human Actions (PEVA), given the past video and an action represented by the relative 3D body pose. By conditioning on kinematic pose trajectories, structured by the joint hierarchy of the body, our model le
arxiv.org



