
늦깎이 공대생의 인공지능 연구실
[해석할 수 있는 기계학습(4-6)] 룰핏(RuleFit) 본문
Friedman과 Popescu(2008)이 제안한 룰핏(RuleFit)알고리즘은 의사결정 규칙의 형태로 자동으로 검출된 상호작용 효과를 포함하는 희박한 선형 모델(Sparse linear models)을 학습합니다.
선형 회귀 모델은 특성값 사이의 상호작용을 설명하지 않습니다. 선형 모델처럼 단순하고 해석 가능한 모델이면서도 특성값의 상호작용을 통합하는 것이 편리하지 않을까요? 룰핏은 이러한 질문에 대한 답이라고 할 수 있습니다. 룰핏은 본래 특성값과 함께 희박한 선형 모델을 학습하고 또한 의사결정 규칙인 다수의 새로운 특성값을 학습합니다. 이러한 새로운 특성값은 원래의 특성값과의 상호작용을 찾아냅니다. 룰핏은 의사결정 트리에서 이와 같은 특성값을 자동으로 생성합니다. 트리를 통과하는 각 경로는 분할된 의사결정을 규칙으로 결합하여 결정 규칙으로 바꿀 수 있습니다. 노트 예측은 버려지고 분할만 의사결정 규칙에 사용됩니다.
이러한 의사결정 트리는 어떻게 나오는걸까요? 이 트리는 관심있는 결과값을 여측하도록 훈련되어 있습니다. 이렇게 되었을 때 분할이 예측 과정에 의미를 갖게 됩니다. 룰핏에서 랜덤 트리와 같이 트리를 많이 생성하는 모든 알고리즘에서 사용할 수 있습니다.
룰핏 논문은 보스턴의 주택 데이터를 사용하여 다음과 같이 설명합니다
"목표는 보스턴 지역의 주택 가격을 예측하는 것이다"
룰핏에서 생성된 규칙 중 하나는 다음과 같습니다.
IF number of rooms > 6.64 AND concentration of nitric oxide < 0.67 THEN 1 ELSE 0
또한 룰핏은 예측에 중요한 일차 형식(Linear form)을 식별하는데 도움이 되는 특성값 중요도 측정 방법을 제공합니다. 특성값 중요도는 회귀 모델의 가중치로 계산됩니다. 중요도 측정은 본래의 특성값("row" 형태 및 많은 의사결정 규칙에서 사용됨)에 대해 집계될 수 있습니다.
거기에다가 룰핏은 특성값을 변경함으로써 예측의 평균 변화를 보여주기 위해 부분 의존성 플롯(Partial dependence plot)을 도입합니다. 부분 의존성 플롯은 어떤 모델에도 사용할 수 있는 모델불특정법(Model-agnostic method) 방법입니다. 이와 관련된 내용은 이후의 챕터에서 설명하고자 합니다.
해석과 예제
룰핏은 결국 선형 모델을 추정하므로 해석은 "일반적인" 선형 모델과 동일합니다. 유일한 차이점은 모델이 의사결정 규칙에서 파생된 새로운 특성값을 가지고 있다는 것입니다. 의사결정 규칙의 특성값은 0과 1로 구성되어있습니다. 규칙의 모든 조건이 충족되면 1, 그렇지 않을 경우 0이 됩니다. 룰핏의 일차 형식(Linear form)에 대해서는 선형 회귀 모델에서와 같은 해석이 존재합니다. 특성값이 한 단계 증가하면 예측 결과는 해당 특성값의 기중치에 의해 변화한다는 것이지요.
아래의 예제에서 룰핏을 사용하여 주어진 날에 대여된 자전거의 대수를 예측해봅니다. 아래의 표에는 룰핏에 의해 생성된 다섯 가지 규칙과 함께 Lasso 가중치와 중요도를 나타냅니다. 계산 방법은 아래 이론 부분에서 다루도록 하겠습니다.
| Description | Weight | Importance |
| days_since_2011 > 111 & weathersit in (“GOOD”, “MISTY”) | 793 | 303 |
| 37.25 <= hum <= 90 | -20 | 272 |
| temp > 13 & days_since_2011 > 554 | 676 | 239 |
| 4 <= windspeed <= 24 | -41 | 202 |
| days_since_2011 > 428 & temp > 5 | 366 | 179 |
가장 중요한 규칙은 다음과 같습니다.
“days_since_2011 > 111 & weathersit in (”GOOD“,”MISTY“)” and the corresponding weight is 793
이는 다음과 같이 해석할 수 있습니다.
다른 모든 특성값이 고정되어 있고 days_since_2011 > 111 & weathersit in (“GOOD”, “MISTY”)일때, 예상 자전거 대여수는 793대가 늘어난다.
총 278개의 규칙이 원래의 8가지 특성값으로부터 만들어졌다. 상당히 많지요! 하지만 Lasso 덕분에 278개 중 0과 다른 가중치를 가진 것은 58개에 불과합니다.
전반적인 특성값 중요도를 계산해보면 기온 및 시간 추세가 가장 중요한 특징임을 알 수 있습니다.

특성값 중요도 측정에는 본래의 특성값과 특성값이 나타내는 모든 의사결정 규칙이 포함됩니다.
해석 견본
해석은 선형 모델과 유사합니다. 다른 모든 특성값이 변경되지 않은 경우 특성값 \(x_j\)가 한 단위씩 변경되면 예측 결과는 \(\beta_j\)에 의해 변경됩니다. 의사결정 규칙의 가중치 해석은 특별한 경우입니다. 의사결정 규칙 \(r_k\)의 모든 조건의 적용되는 경우, 예측 결과는 \(\alpha_k\)(선형 모델에서 규칙 \(r_k\)의 학습된 가중치)만큼 변화합니다.
분류의 경우(선형 회귀 분석 대신 로지스틱 회귀 분석 사용시), 의사결정 규칙 \(r_k\)의 모든 조건이 적용되는 경우 사건이 발생하거나 발생하지 않을 때의 확률은 \(\alpha_k\)의 인수로 변합니다.
이론
룰핏 알고리즘의 기술적 세부사항에 대해 좀 더 자세히 알아보도록 합시다. 룰핏은 두 가지 구성요소로 구성되어 있습니다. 첫 번째 구성요소는 의사결정 트리에서 "규칙"을 생성하고 두 번째 구성요소는 본래의 특성값과 새 규칙을 입력으로 선형 모델에 맞춥니다(그래서 "RuleFit"이라는 이름인 것이지요).
1단계: 규칙 생성
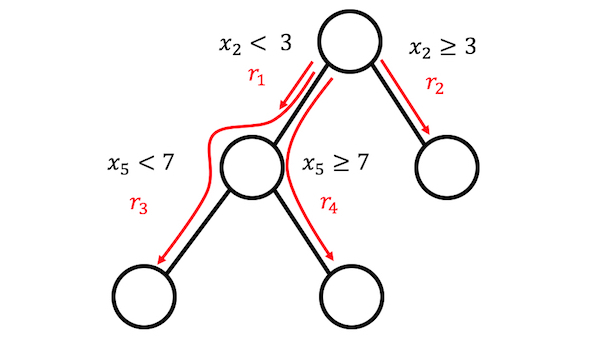
규칙은 어떤 모습일까요? 알고리즘에 의해 생성된 규칙은 간단한 형식을 가지고 있습니다. 예를 들어 다음과 같이 말이지요.
If x2 < 3 AND x5 < 7 THEN 1 ELSE 0
이 규칙은 의사결정 트리를 분해하여 구성됩니다. 트리의 노드에 대한 모든 경로는 의사결정 규칙으로 변환될 수 있습니다. 규칙에 사용되는 트리는 목표 결과값을 예측하는 데 적합합니다. 따라서 분할 및 결과 규칙은 원하는 결과를 예측하도록 최적화됩니다. 특정 노드로 이어지는 이진 결정을 "AND"로 연결하기만 하면 됩니다. 그리고 보시는 바와 같이 규칙이 생성됩니다. 다양하고 의미 있는 규칙을 많이 만드는 것이 바람직합니다. 경사(Gradient) 부스팅은 원래 특성값은 X로 y를 회귀시키거나 분류하여 의사결정 트리의 앙상블에 맞추는데 사용됩니다. 각 결과 트리는 여러 개의 규칙으로 변환됩니다. 트리를 신장시켰을 뿐 아니라 어떤 트리 앙상블 알고리즘도 룰핏을 위한 트리를 생성하는데 사용될 수 있습니다. 트리 앙상블은 다음과 같은 일반적인 공식으로 설명할 수 있습니다.
$$f(x)=a_0+\sum_{m=1}^M{}a_m{}f_m(X)$$
M은 트리의 갯수이고 \(f_m(x)\)는 m번째 트리의 예측 함수를 나타냅니다. \(\alpha\)는 가중치입니다. 한 앙상블, 랜덤 포레스트, AdaBoost와 MART는 트리 앙상블을 생산하며, 룰핏에 사용할 수 있습니다.
앙상블의 모든 트리로부터 규칙을 만듭니다. 각 규칙 \(r_m\)은 다음과 같습니다.
$$r_m(x)=\prod_{j\in\text{T}_m}I(x_j\in{}s_{jm})$$
\(T_m\)은 m번째 트리에서 사용된 특성값의 집합을, I는 특성값 \(x_j\)가 j번째 특성값 대한 값의 지정된 부분집합이 있을 때(트리 분할에 의해 지정됨) 1이고, 그렇지 않으면 0인 지시함수입니다. 수치 특성값의 경우, \(s_{jm}\)은 특성값의 범위 간격을 나타냅니다. 간격은 두 가지 경우 중 하나와 같습니다.
$$x_{s_{jm},\text{lower}}<x_j$$
$$x_j<x_{s_{jm},upper}$$
이러한 특성값에서 더 많은 분열이 더 복잡한 간격을 나타낼 수 있습니다. 카테고리형 특성값의 경우 부분 집합에는 특성값의 특정한 카테고리가 포함됩니다.
자전거 대여 데이터셋에 대한 식은 다음과 같이 표현할 수 있습니다.
$$r_{17}(x)=I(x_{\text{temp}}<15)\cdot{}I(x_{\text{weather}}\in\{\text{good},\text{cloudy}\})\cdot{}I(10\leq{}x_{\text{windspeed}}<20)$$
이 규칙은 세 가지 조건이 모두 충족되면 1을 반환하고, 그렇지 않으면 0을 반환합니다. 룰핏은 리프 노드뿐만 아니라 트리에서 가능한 모든 규칙을 추출합니다. 그리하여 다음과 같은 또 다른 규칙이 생성됩니다.
$$r_{18}(x)=I(x_{\text{temp}}<15)\cdot{}I(x_{\text{weather}}\in\{\text{good},\text{cloudy}\})$$
말단 노드 \(t_m\)가 각각 있는 M개의 트리 앙상블에서 생성된 규칙의 수는 다음과 같습니다.
$$K=\sum_{m=1}^M2(t_m-1)$$
룰핏의 저자들이 도입한 트릭은 길이가 다른 여러 가지 다양한 규칙이 생성될 수 있도록 무작위 깊이의 트리를 익히는 것입니다. 각 노드에서 예측된 값을 버리고 노드로 이어지는 조건만 유지한 다음 노드에서 규칙을 생성한다는 점에 유의합니다. 의사결정 규칙의 가중치는 룰핏의 2단계에서 이루어집니다.
1단계에서 볼 수 있는 다른 방법으로서 룰핏은 본래의 특성값에서 새로운 특성값 집합을 생성합니다. 이러한 특성값은 바이너리값이며 본래의 특성값의 상당히 복잡한 상호작용을 나타낼 수 있습니다. 규칙은 예측된 작업을 최대화하기 위해 선택됩니다. 규칙은 공변 행렬 X에서 자동으로 생성됩니다. 규칙을 단순하게 본래의 특성값에 기초하여 새로운 특성값으로 간주할 수 있습니다.
2단계: 희박한 선형 모델
1단계에서 많은 규칙을 얻습니다. 1단계는 특성값 변환으로만 볼 수 있기 때문에, 아직까지 모델을 맞추는 작업이 끝나지 않았습니다. 또한, 규칙의 수를 줄여야만 합니다. 규칙 외에도 본래의 데이터셋의 "raw" 특성값이 모두 희박한 선형 모델에서도 사용될 것입니다. 모든 규칙과 모든 본래의 특성값은 선형 모델에서의 특성값이 되고 가중치의 추정치를 얻게됩니다. 트리가 y와 x 사이의 단순한 선형 관계를 나타내지 못하기 때문에 본래의 특성값이 추가됩니다. 희박한 선형 모델을 훈련하기 전에 본래의 특성값이 이상치(outlier)에 대해 보다 견고하게 되도록 동등화(winsorize)합니다.
$$l_j^*(x_j)=min(\delta_j^+,max(\delta_j^-,x_j))$$
\(\delta_j^-\)와 \(\delta_j^+\)은 특성값 \(x_j\)의 데이터 분포량 \(\delta\)를 나타냅니다. \(\delta\)에 대해 0.05를 선택하면 5% 최저값 또는 5% 최고값에 있는 특성값 \(x_j\)의 값이 각각 5% 또는 95%의 분위수로 설정됩니다. 경험상 \(\delta\) = 0.025를 선택할 수 있습니다. 또한 일차항(linear terms)은 일반적인 의사결정 규칙과 동일한 우선 순위를 갖도록 정규화되어야 합니다.
$$l_j(x_j)=0.4\cdot{}l^*_j(x_j)/std(l^*_j(x_j))$$
여기서 0.4는 규칙의 평균 표준 편차로서 \(s_k\sim{}U(0,1)\)가 균일하게 분포되어 있습니다.
두 가지 유형의 특성값을 결합하여 새로운 특성값 행렬을 생성하고 희박한 선형 모델을 다음과 같은 구조로 Lasso로 학습합니다.
$$\hat{f}(x)=\hat{\beta}_0+\sum_{k=1}^K\hat{\alpha}_k{}r_k(x)+\sum_{j=1}^p\hat{\beta}_j{}l_j(x_j)$$
여기서 \(\hat{\alpha}\)는 규칙 특성값에 대한 추정 가중치 벡터, \(\hat{\beta}\)는 본래의 특성값에 대한 가중치 벡터입니다. 룰핏은 Lasso를 사용하기 때문에, 손실함수는 일부 가중치가 영점 추정치를 얻도록 하는 추가 제약 조건을 얻게됩니다.
$$(\{\hat{\alpha}\}_1^K,\{\hat{\beta}\}_0^p)=argmin_{\{\hat{\alpha}\}_1^K,\{\hat{\beta}\}_0^p}\sum_{i=1}^n{}L(y^{(i)},f(x^{(i)}))+\lambda\cdot\left(\sum_{k=1}^K|\alpha_k|+\sum_{j=1}^p|b_j|\right)$$
그 결과는 모든 본래의 특성값과 규칙에 대해 선형 효과를 갖는 선형 모델입니다. 해석은 선형 모델과 동일하며, 유일한 차이점은 일부 특성값이 2진수 규칙이라는 것이지요.
3단계(선택): 특성값 중요도
본래의 특성값의 일차항에 대해 특성값 중요도는 표준화 예측 변수를 사용하여 측정합니다.
$$I_j=|\hat{\beta}_j|\cdot{}std(l_j(x_j))$$
\(\beta_j\)는 Lasso 모델의 가중치이고 \(std(l_j(x_j))\)는 데이터에 대한 일차항의 표준 편차입니다.
의사결정 규칙의 관점에서 중요도는 다음과 같은 공식으로 계산합니다.
$$I_k=|\hat{\alpha}_k|\cdot\sqrt{s_k(1-s_k)}$$
\(\hat{\alpha}_k\)는 의사결정 규칙과 관련된 Lasso 가중치를 나타내고 \(s_k\)는 데이터에서 특성값의 서포트(Support)로, 의사결정 규칙이 적용되는 데이터 포인트의 백분율을 나타냅니다(\(r_k(x)=0\)).
$$s_k=\frac{1}{n}\sum_{i=1}^n{}r_k(x^{(i)})$$
특성값은 일차항으로 나타나며, 많은 의사결정 규칙에서도 발생할 수 있습니다. 특성값의 총 중요도를 어떻게 측정하게될까요? 특성값 중요도 \(J_j(x)\)는 각 개별 예측에 대해 측정할 수 있습니다.
$$J_j(x)=I_j(x)+\sum_{x_j\in{}r_k}I_k(x)/m_k$$
여기서 \(I_l\)은 일차항의 중요도이고 \(I_k\)는 \(x_j\)가 나타나는 의사결정 규칙의 중요도이고 \(m_k\)는 규칙 \(r_k\)를 구성하는 특성값의 갯수입니다. 모든 인스턴스에서 특성값 중요도를 추가하면 전반적인 특성값 중요도를 계산할 수 있습니다.
$$J_j(X)=\sum_{i=1}^n{}J_j(x^{(i)})$$
인스턴스의 부분집합을 선택하고 이 그룹에 대한 특성값 중요도를 계산할 수 있습니다.
장점
룰핏은 특성값 상호작용을 선형 모델에 자동으로 추가합니다. 따라서 상호작용 공식을 직접 추가해야 하는 선형 모델의 문제를 해결하고 비선형 관계를 모델링하는 문제에 약간 도움이 될 수 있습니다.
룰핏은 분류 작업과 회귀 작업을 모두 처리할 수 있습니다.
생성된 규칙은 2진 의사결정 규칙이므로 해석하기가 쉽습니다. 규칙은 인스턴스에 적용되거나 적용되지 않습니다. 규칙 내의 조건의 갯수가 너무 크지 않은 경우에만 양호한 해석력(Interpretability)이 보장됩니다. 1에서 3까지의 조건이 있는 규칙은 합리적인 것 같습니다. 이는 트리 앙상블에 있는 트리의 최대 깊이가 3이라는 것을 의미합니다.
모델에 많은 규칙이 있더라도 몯느 경우에 적용되는 것은 아닙니다. 개별 인스턴스의 경우 소수의 규칙만 적용됩니다(0이 아닌 가중치). 이는 지역적 해석력(Local interpretability)을 향상시킵니다.
룰핏은 유용한 진단 도구를 제안합니다. 이러한 도구는 모델에 구애받지 않으므로 모델불특정법(Model-agnostic) 파트에서 다룰 것입니다.
단점
종종 룰핏은 Lasso 모델에서 0이 아닌 가중치를 얻는 많은 규칙을 만듭니다. 해석력은 모델에서 특성값의 수가 증가함에 따라 저하됩니다. 유망한 해결책은 특성값 효과를 단조롭게 하도록 강제하는 것인데, 이는 특성값의 증가는 예측값의 증가를 이끌어야 한다는 것을 의미합니다.
몇몇 논문들은 룰핏의 좋은 성과가 종종 랜덤 포레스트의 예측 성과에 가깝자고 주장합니다. 그러나 몇 안되는 경우에는 성과가 그리 좋지 못합니다. 문제를 해결하고 어떻게 동작되는지 확인해보셨으면 합니다.
룰핏 절차의 최종 생성물은 추가적인 화려한 특성(의사결정 규칙)을 가진 선형 모델입니다. 그러나 이는 선형 모델이기 때문에, 가중치 해석은 여전히 직관적이지 않습니다. 일반적인 선형 회귀 모델과 동일한 "각주"가 제공됩니다. " ... 모든 특성값이 고정되어 있는것으로 보아" 중복되는 규칙이 있으면 좀 더 까다로워집니다. 예를 들어 자전거 대여수 예측에 대한 하나의 의사결정 규칙(특성값)은 "temp > 10"일 수 있고, 다른 규칙은 "temp > 15 & weather = 'GOOD'"일 수도 있습니다. 날씨가 좋고 기온이 15도 이상이면 기온 특성값은 자동으로 10도보다 높아집니다. 두 번째 규칙이 적용되는 경우에는 첫 번째 규칙도 적용됩니다. 두 번째 규칙의 추정 가중치에 대한 해석은 "다른 모든 특성값이 고정되어 있다고 가정하면, 날씨가 좋고 기온이 15도 이상일 때 자전거 대여수의 예측 횟수는 \(\beta_2\)만큼 증가한다"라고 할 수 있습니다. 그러나 이제 규칙 2가 적용되면 규칙 1도 적용되고 해석도 비논리적이기 때문에 '다른 모든 특성값 고정'이 문제가 된다는 것은 정말로 명백해집니다.
소프트웨어 및 대안
룰핏 알고리즘은 Fokkema와 Christopersen(2017)에 의해 R에서 구현되었으며, Github에서 Python 버전을 사용하실 수 있습니다.
매우 유사한 프레임워크로 skope-rules가 있습니다. 이 프레임워크는 앙상블에서 규칙을 추출하는 Python 모듈입니다. 이 프레임워크는 또한 최종 규칙을 배우는 방식에 따라 달라집니다. 첫째, skope-rules는 리콜 및 정밀도 임계값을 기준으로 저성능 규칙을 제거합니다. 그런 다음, 규칙의 논리적 용어(변수 + 더 큰/더 작은 연산자)와 성능(F1-score)의 다양성에 근거한 선택을 수행함으로써 중복 및 유사한 규칙을 제거합니다. 마지막 단계는 Lasso를 사용하는 것에 의존하지 않고, 규칙을 구성하는 F1-score와 논리적인 용어만을 고려합니다.
참고자료: https://christophm.github.io/interpretable-ml-book/rulefit.html
4.6 RuleFit | Interpretable Machine Learning
Machine learning algorithms usually operate as black boxes and it is unclear how they derived a certain decision. This book is a guide for practitioners to make machine learning decisions interpretable.
christophm.github.io
'해석할 수 있는 기계학습 > 4. 해석할 수 있는 모델' 카테고리의 다른 글
| [해석할 수 있는 기계학습(4-7)] 기타 해석할 수 있는 모델 (0) | 2020.03.07 |
|---|---|
| [해석할 수 있는 기계학습(4-5)] 의사결정 규칙(Decision Rule) (0) | 2020.02.24 |
| [해석할 수 있는 기계학습(4-4)] 의사결정 트리(Decision Tree) (1) | 2020.01.04 |
| [해석할 수 있는 기계학습(4-3)] GLM, GAM 및 상호작용 (3) | 2019.12.26 |
| [해석할 수 있는 기계학습(4-2)] 로지스틱 회귀 (0) | 2019.12.24 |



